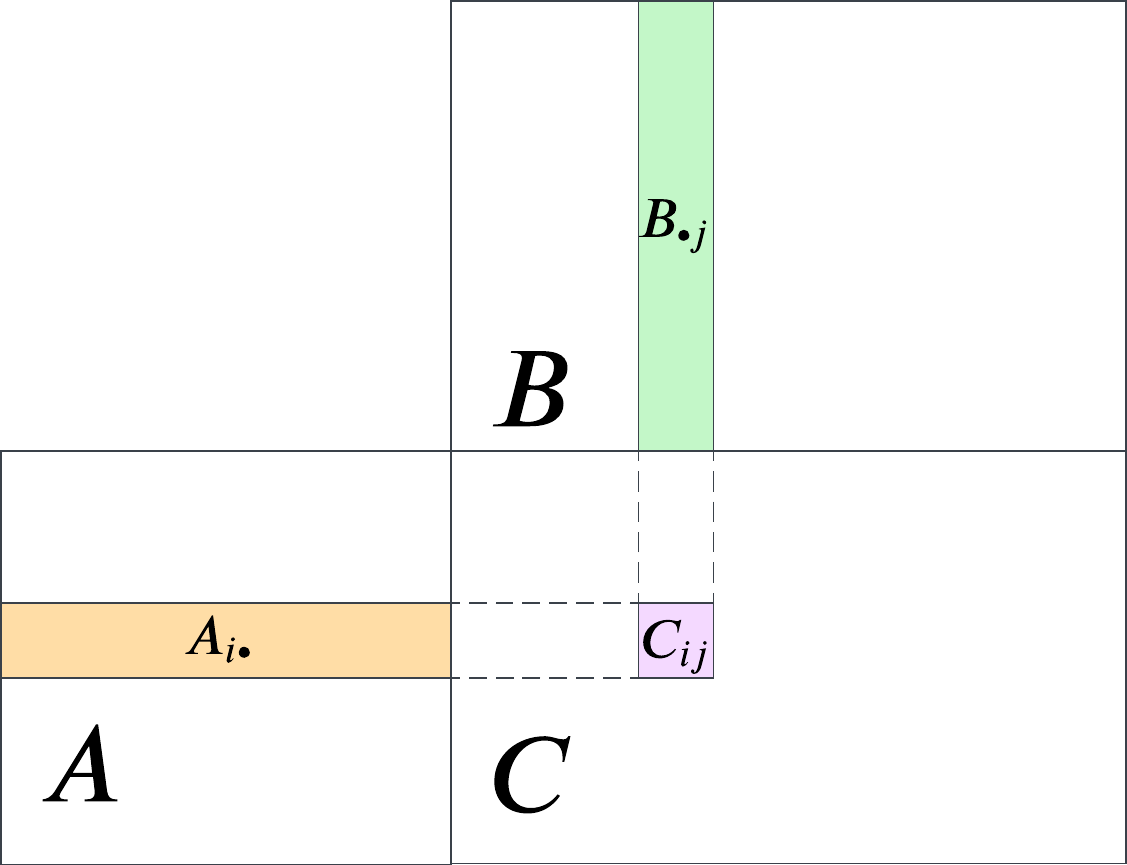
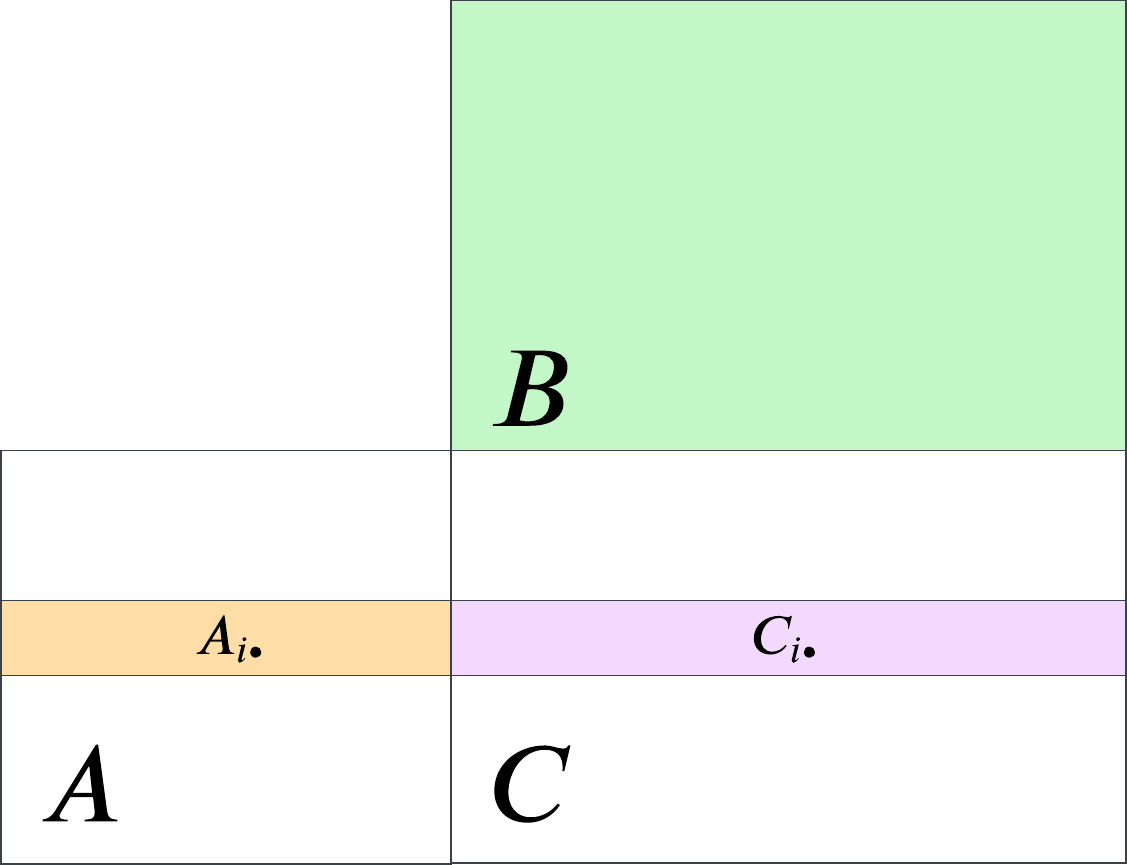
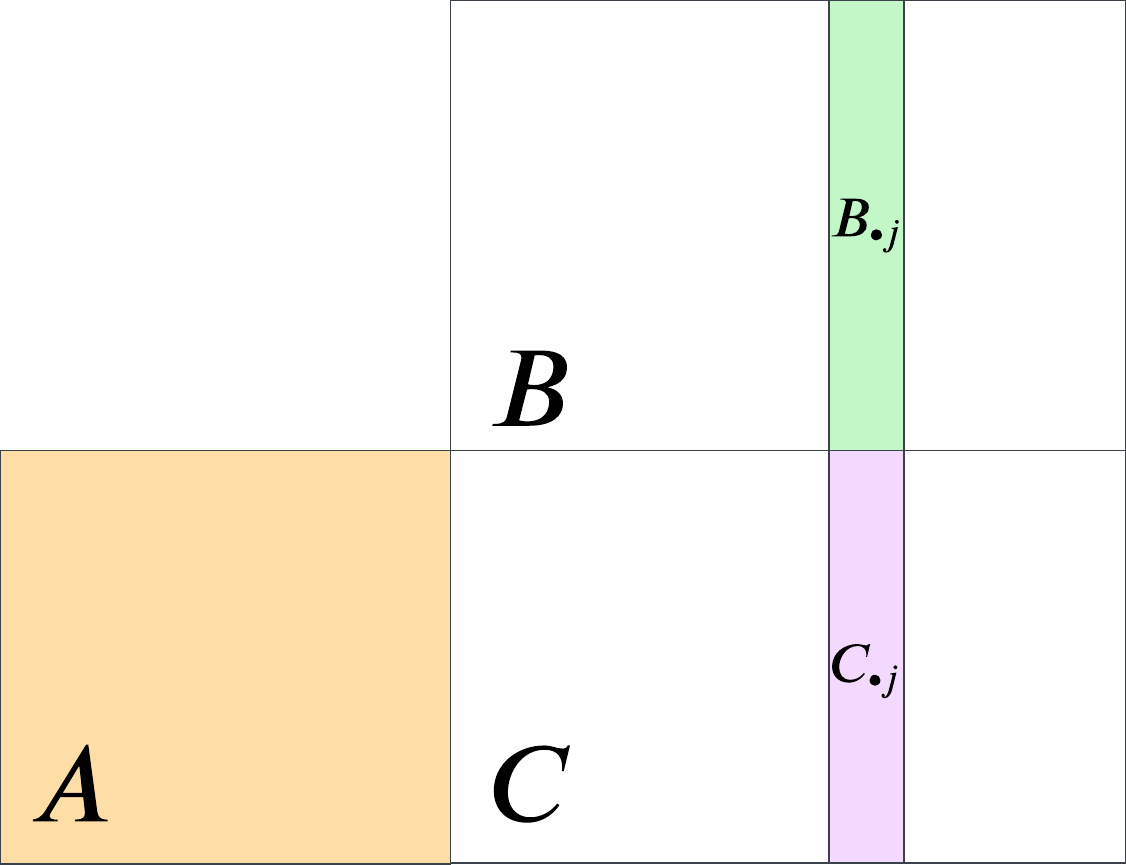
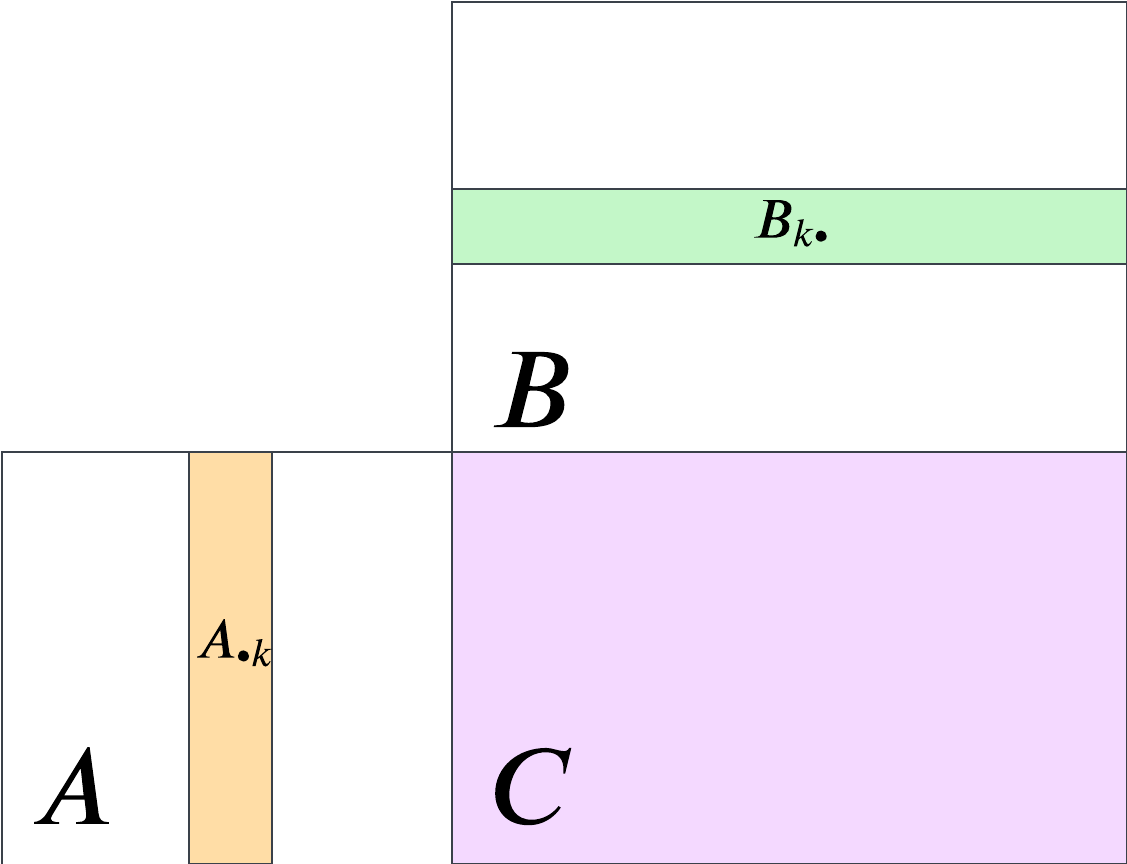
pc_approx_scor <- function(pc, num_pcs = 1) {
Q = pc$x[,1:num_pcs] # first PC scores
V = pc$rotation[,1:num_pcs] # first PC loadings
mu = pc$center # variable means
scor_hat = Q %*% t(V) + mu
return(scor_hat)
}
hat_scor_1 = pc_approx_scor(pc, num_pcs = 1)
hat_scor_5 = pc_approx_scor(pc, num_pcs = 5)
# heatmaps: original scor vs rank-1 approximation
cols <- colorRampPalette(c("navy", "white", "firebrick3"))(100)
zmin <- min(c(as.matrix(scor), as.matrix(hat_scor_1), as.matrix(hat_scor_5)))
zmax <- max(c(as.matrix(scor), as.matrix(hat_scor_1), as.matrix(hat_scor_5)))
plot_heat <- function(mat, main = "") {
m <- as.matrix(mat)
image(1:ncol(m), 1:nrow(m), t(apply(m, 2, rev)),
col = cols, axes = FALSE, xlab = "", ylab = "",
main = main, zlim = c(zmin, zmax))
axis(1, at = 1:ncol(m), labels = colnames(m), las = 2)
axis(2, at = 1:nrow(m), labels = rev(rownames(m)), las = 2)
box()
}
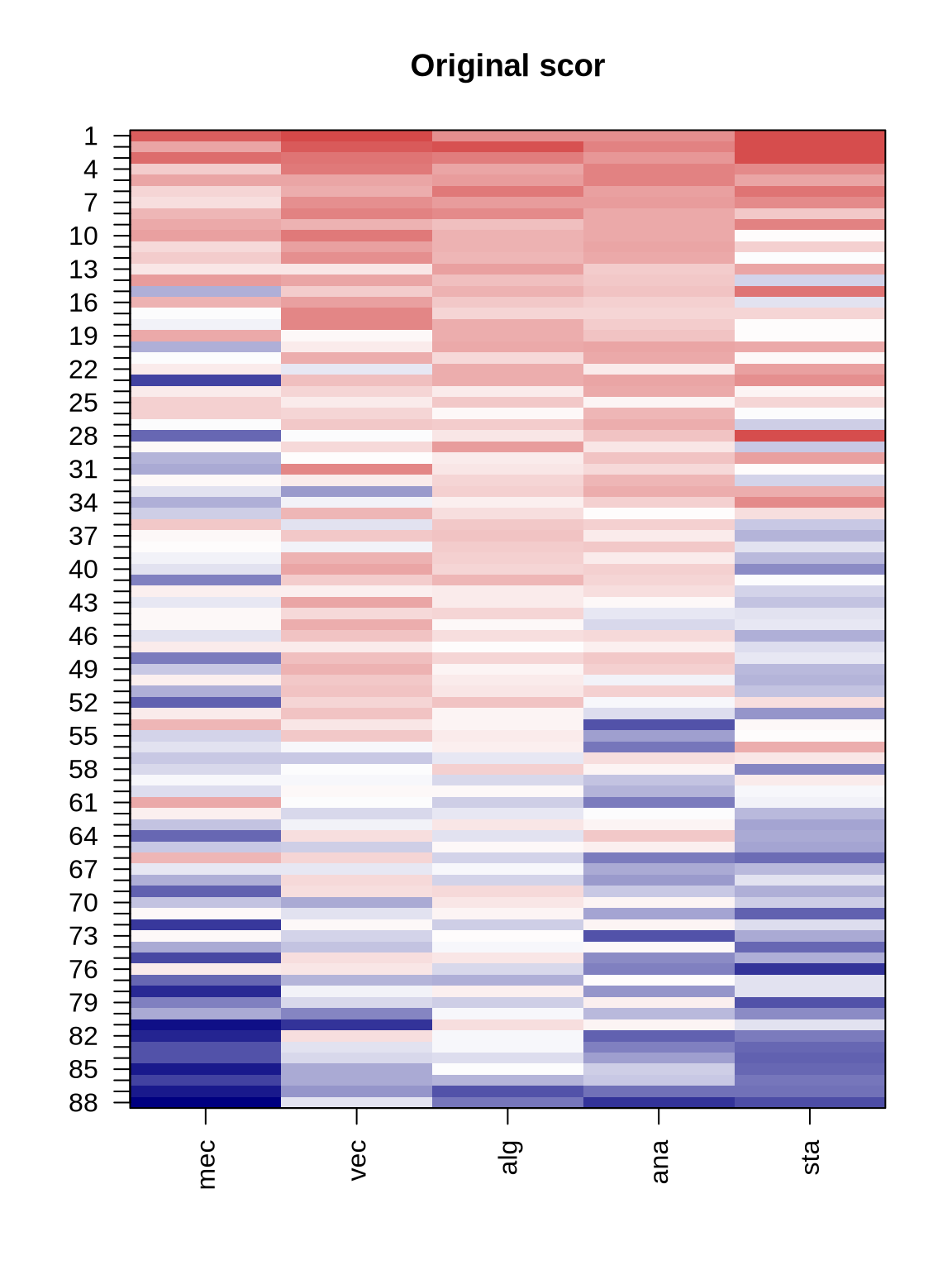
plot_heat(scor, "Original scor")
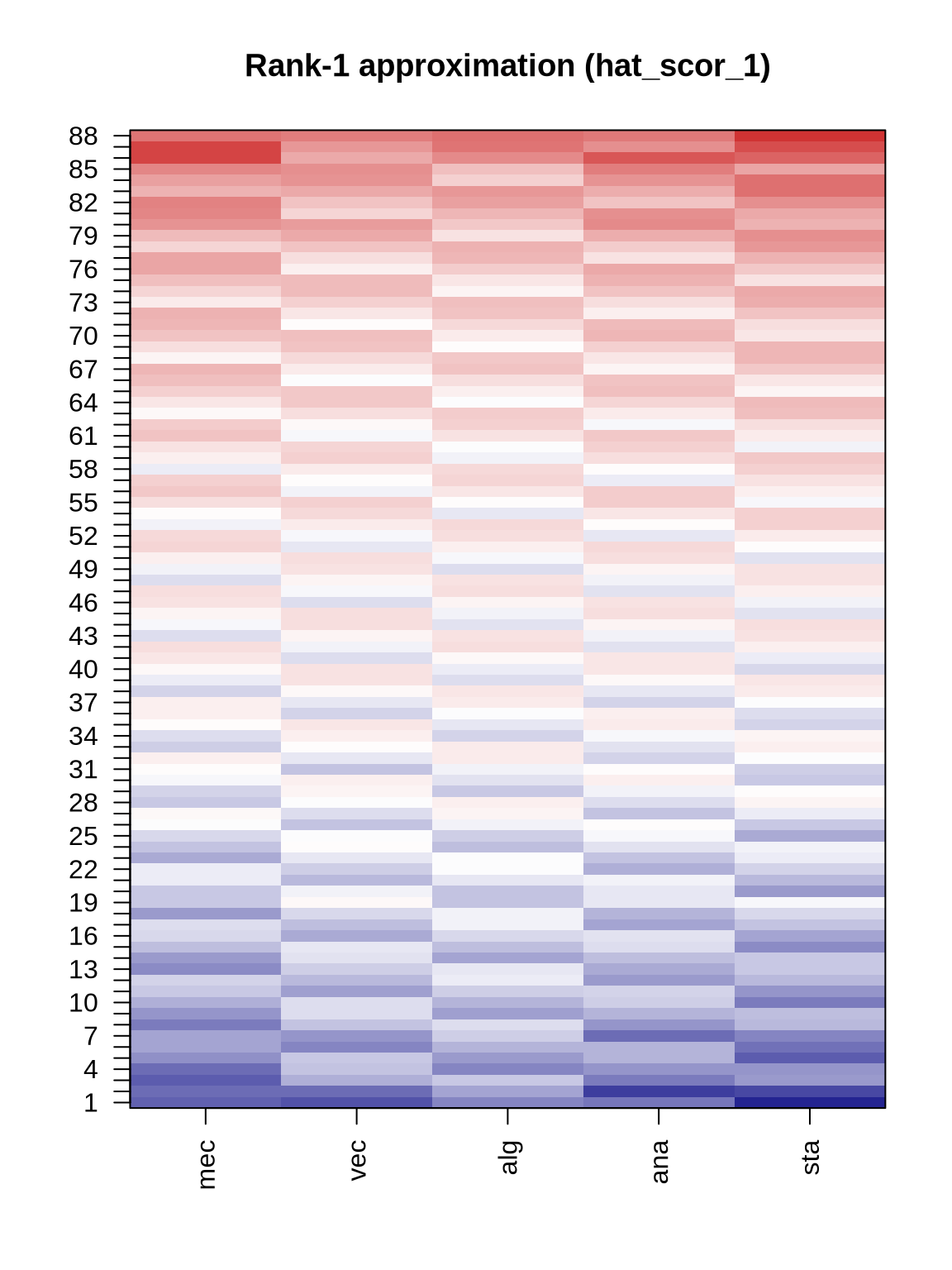
plot_heat(hat_scor_1, "Rank-1 approximation (hat_scor_1)")
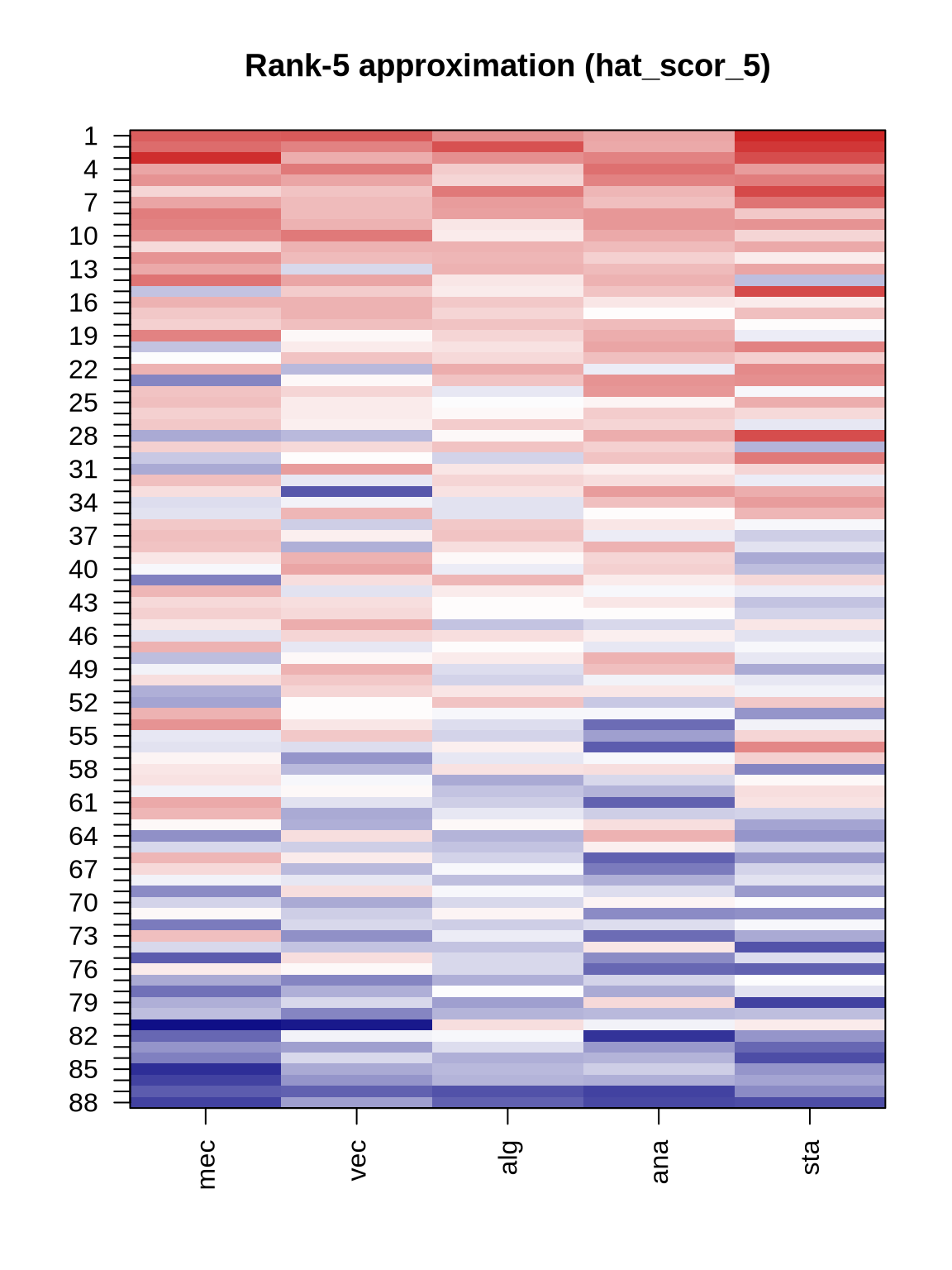
plot_heat(hat_scor_5, "Rank-5 approximation (hat_scor_5)")