Linear algebra for data science, Part 2
PSTAT 234 (Fall 2025)
PCA: Visualizing Component Contributions
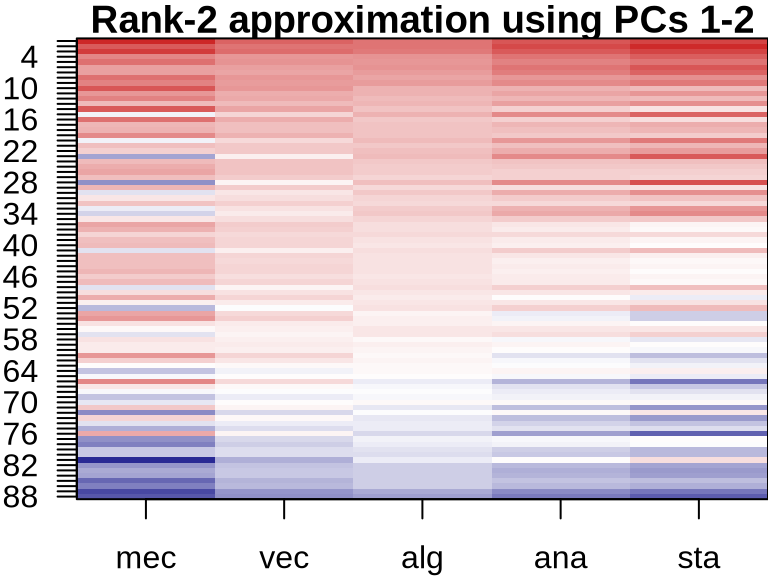
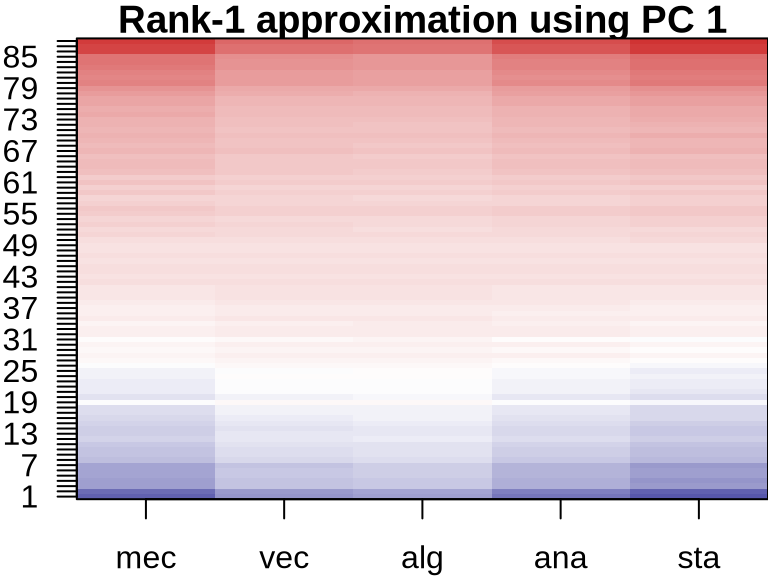
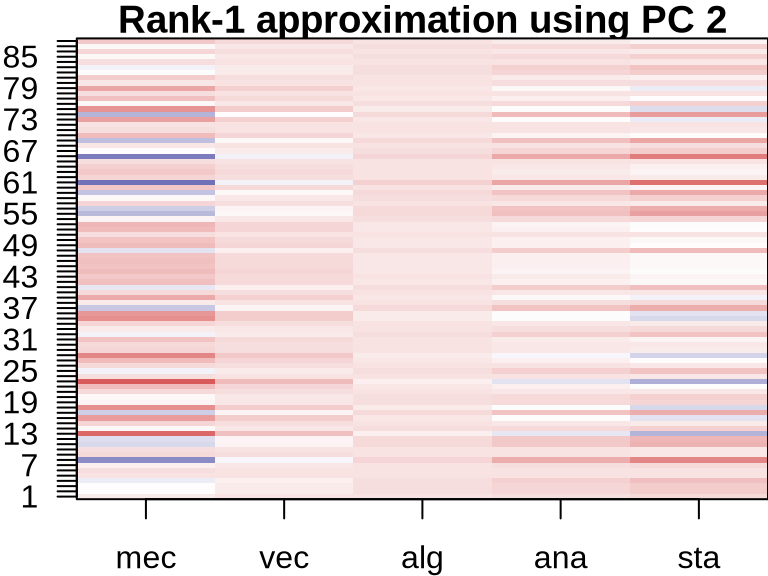


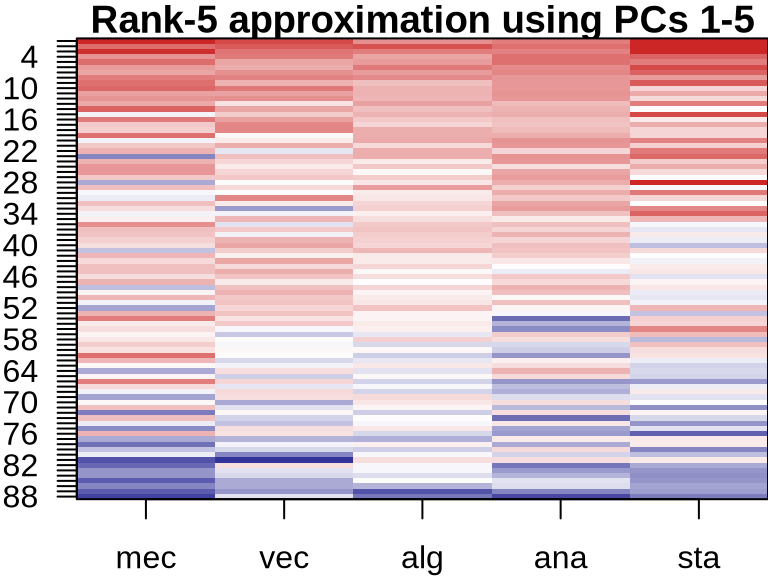
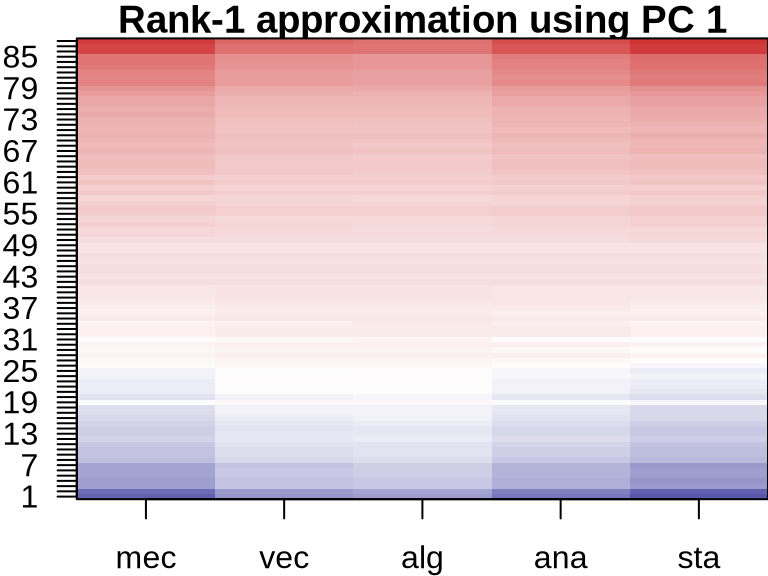
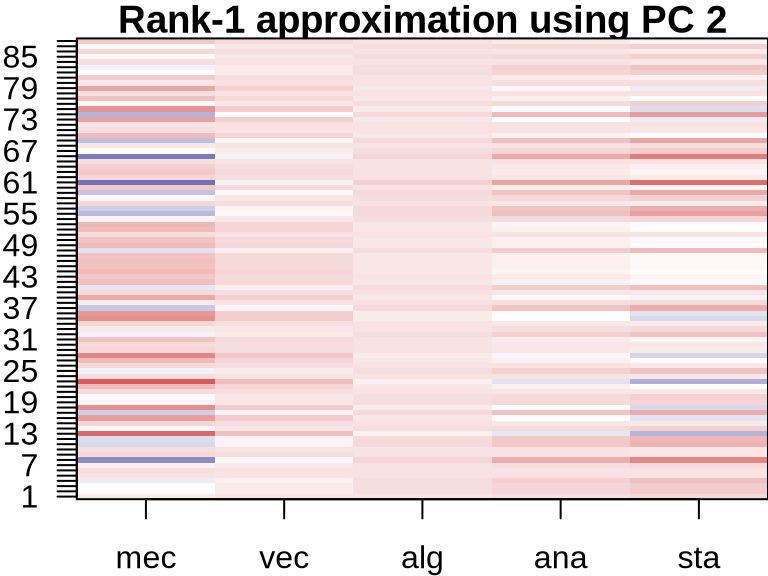
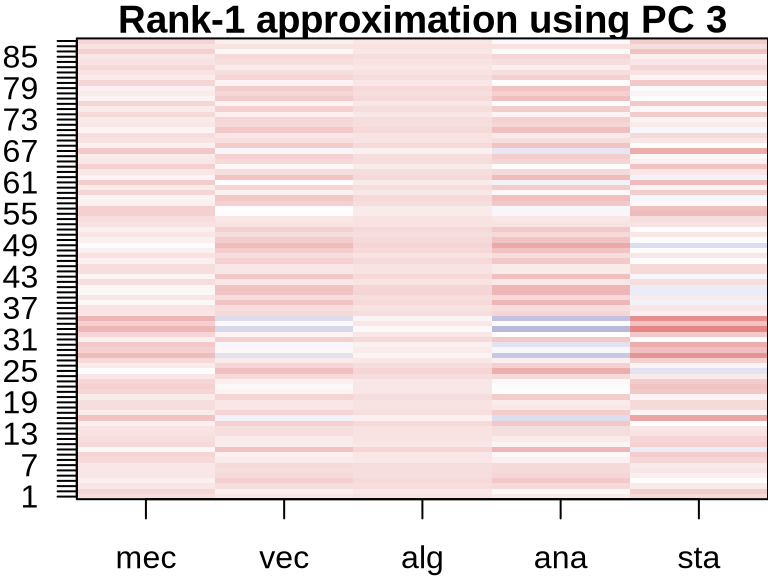
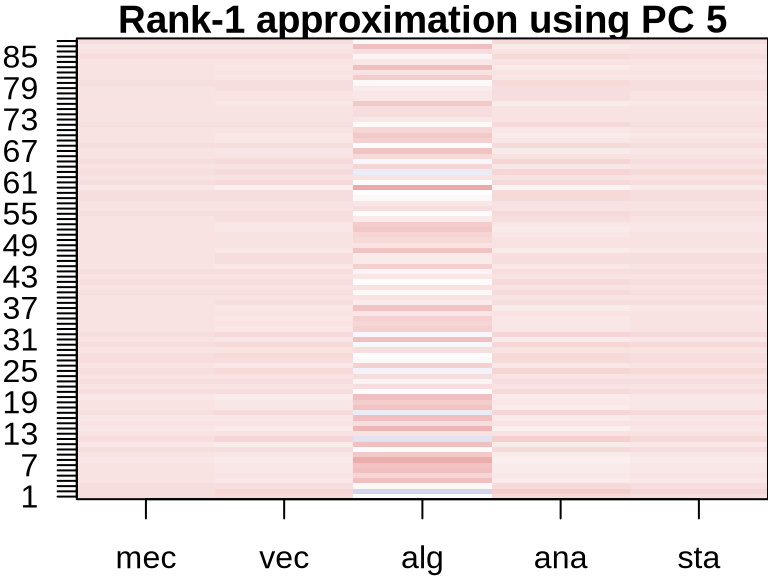
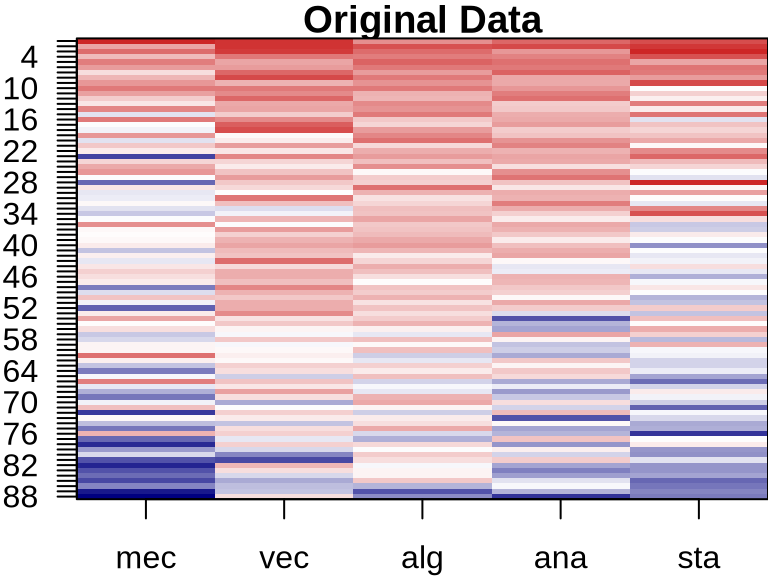




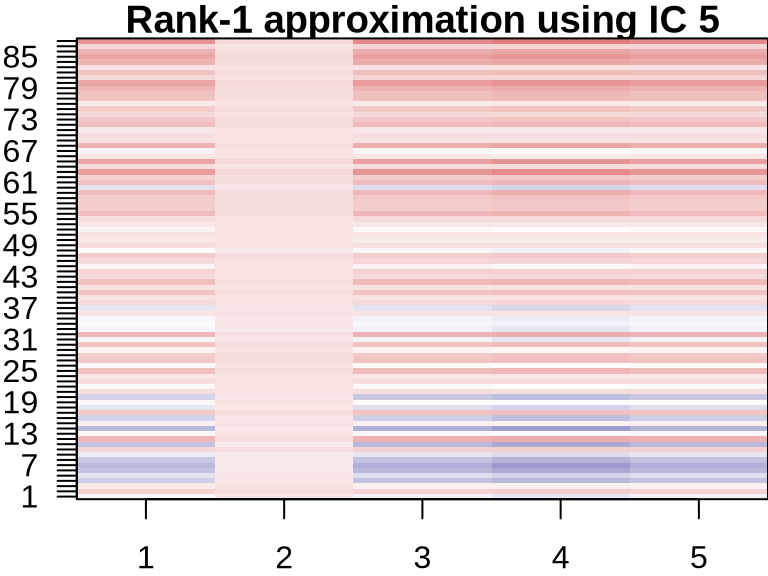
ICA: Visualizing Component Contributions
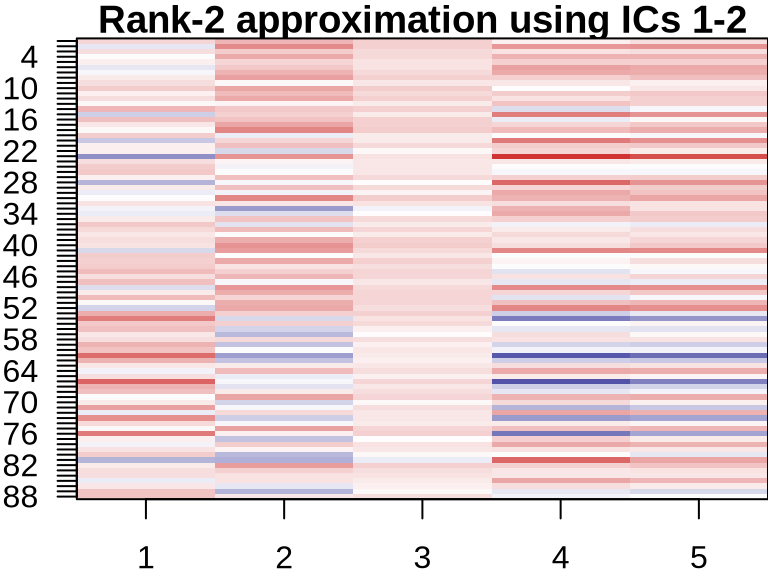
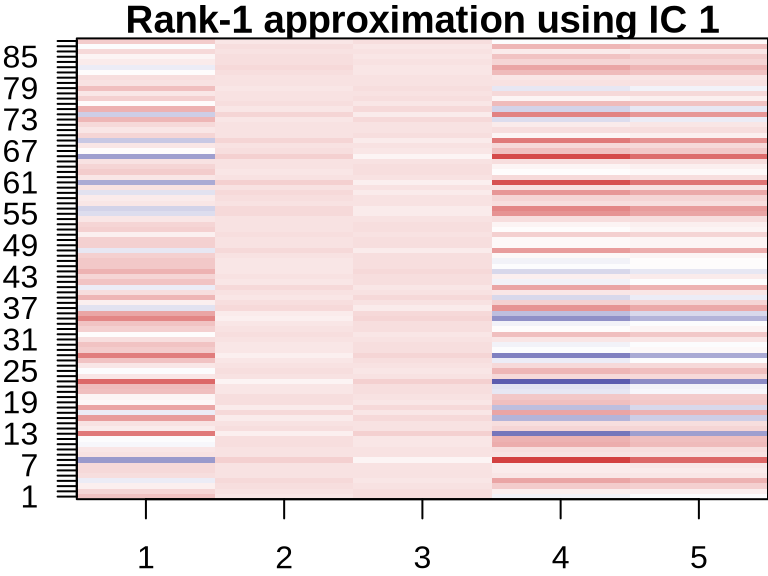
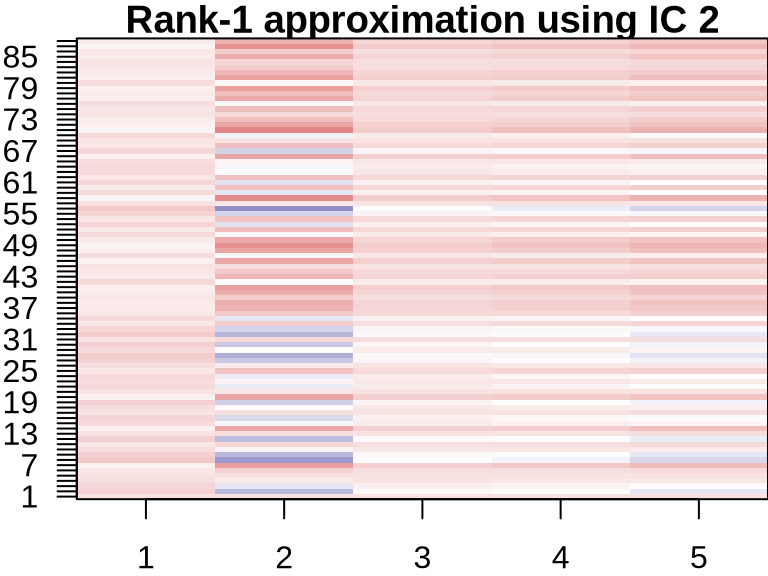


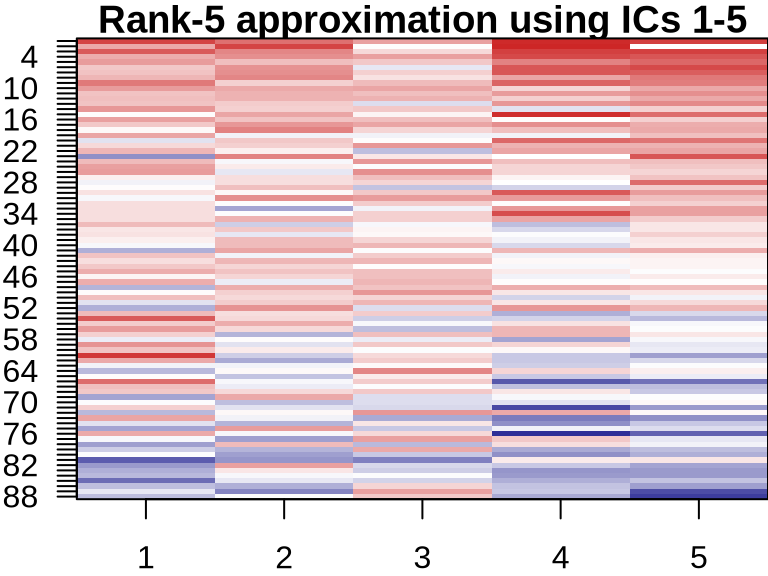
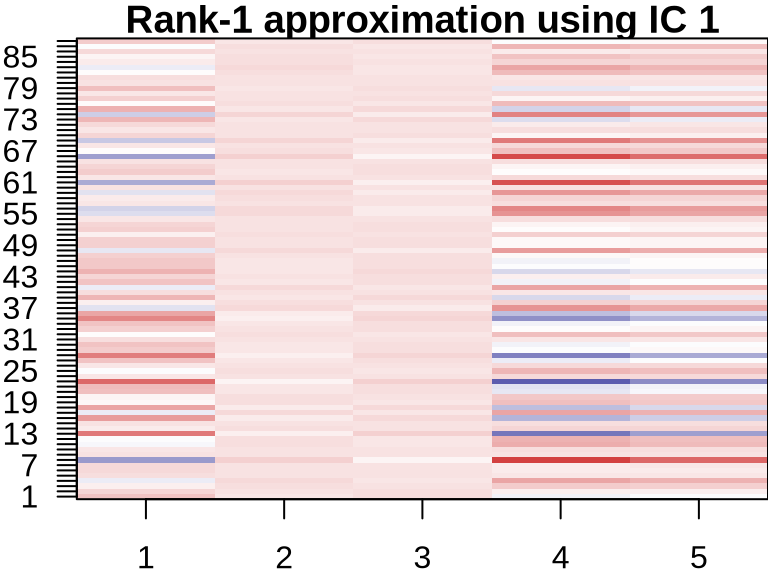
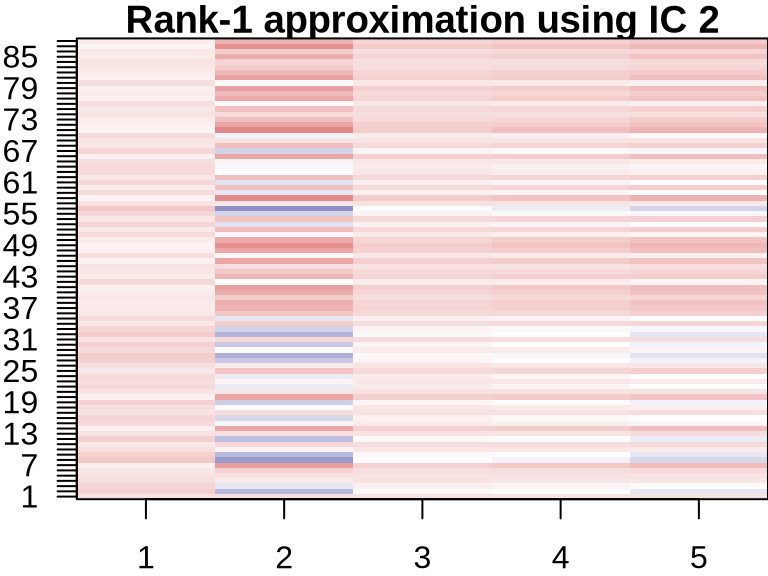
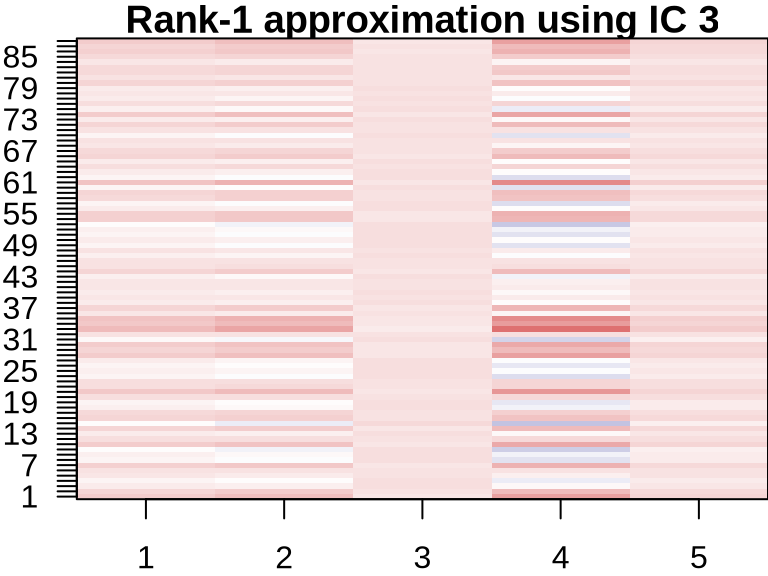
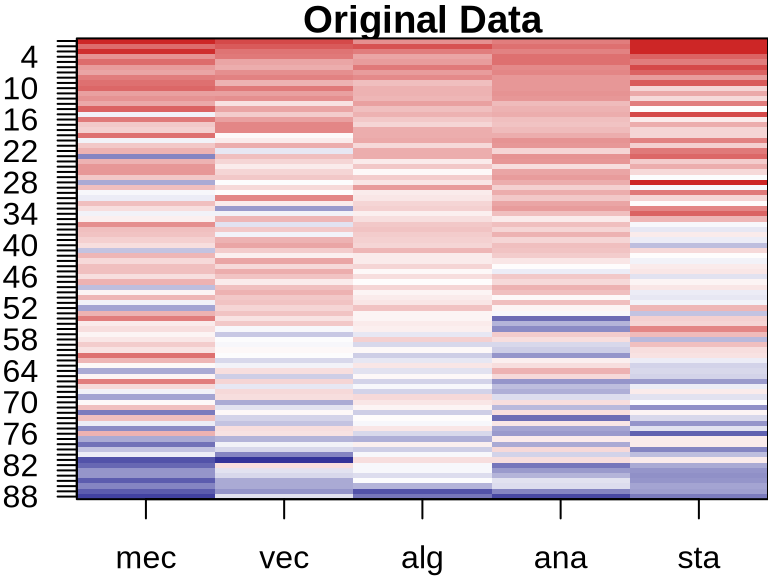




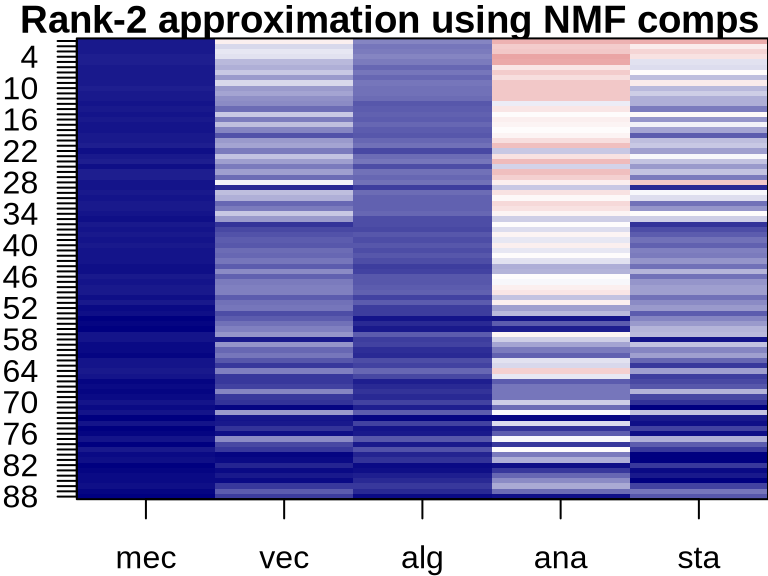
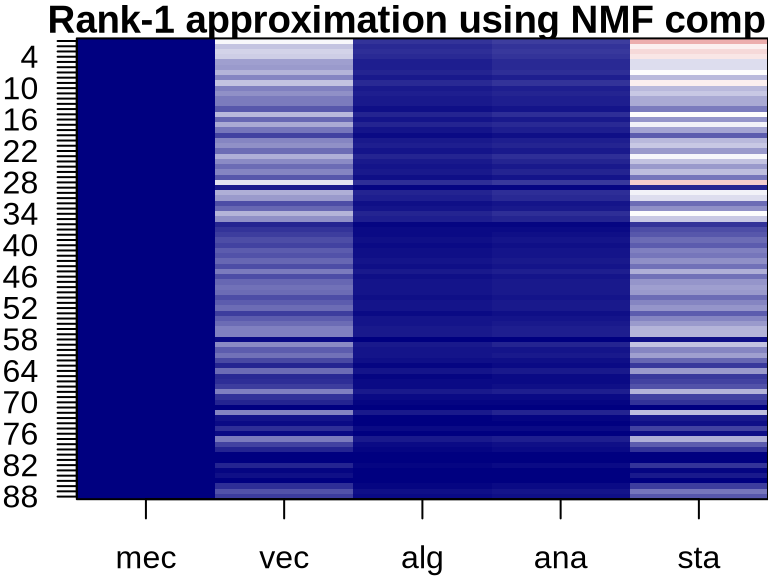
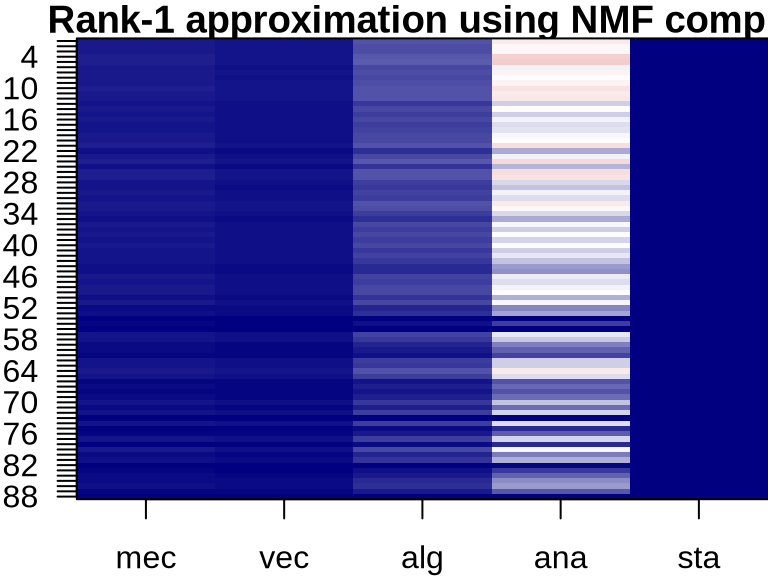
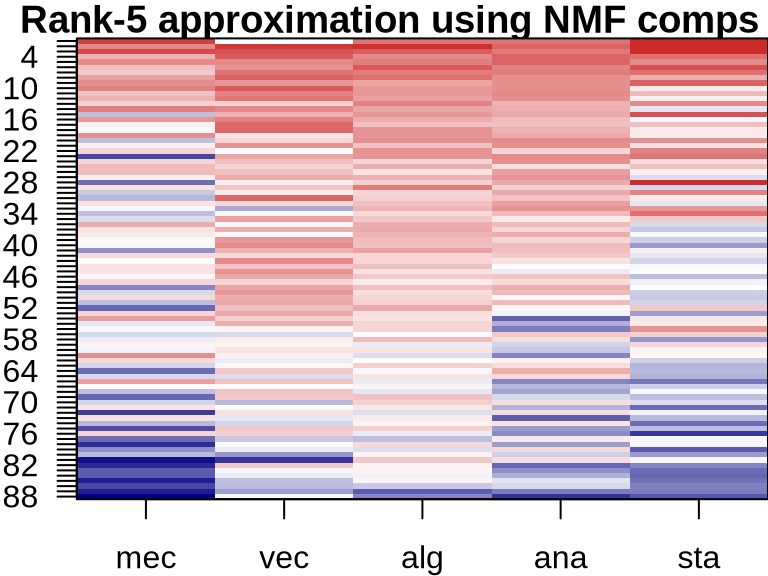
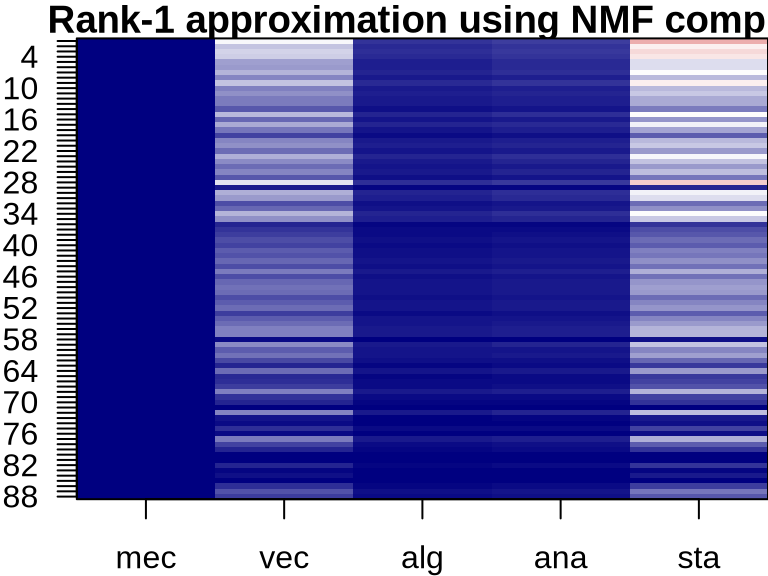
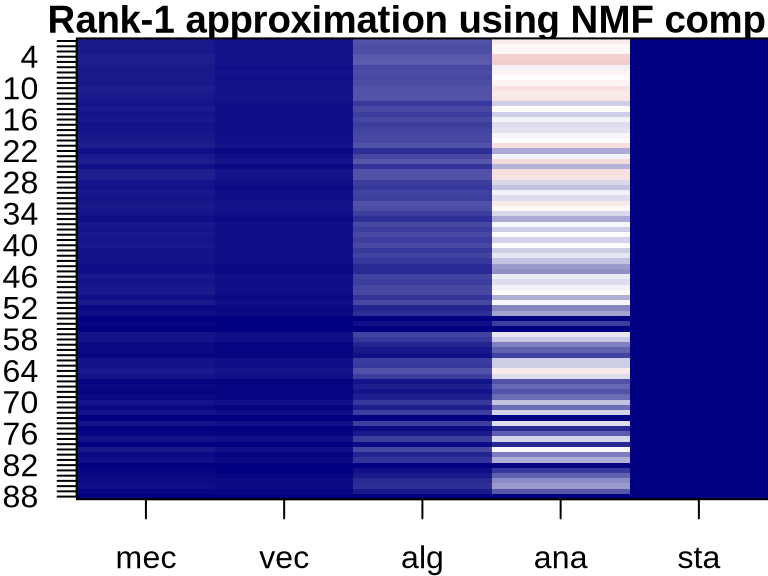
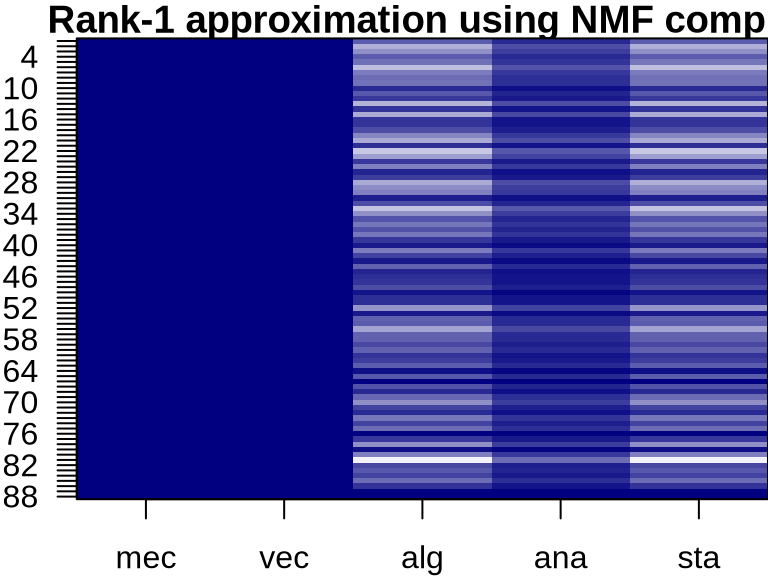
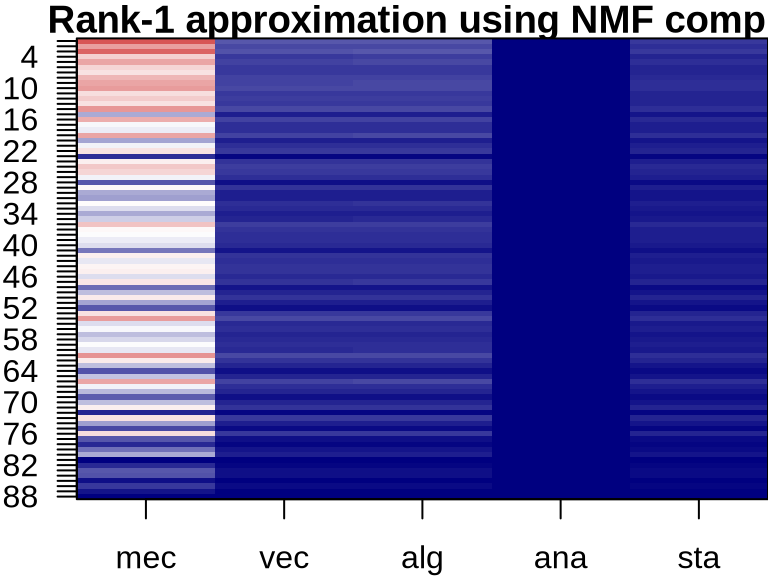
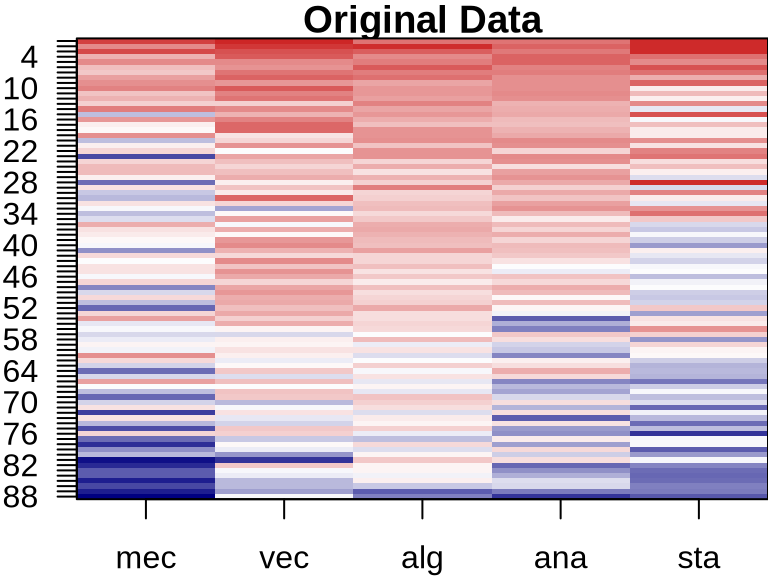
NMF: Visualizing Component Contributions






Independent Components Analysis
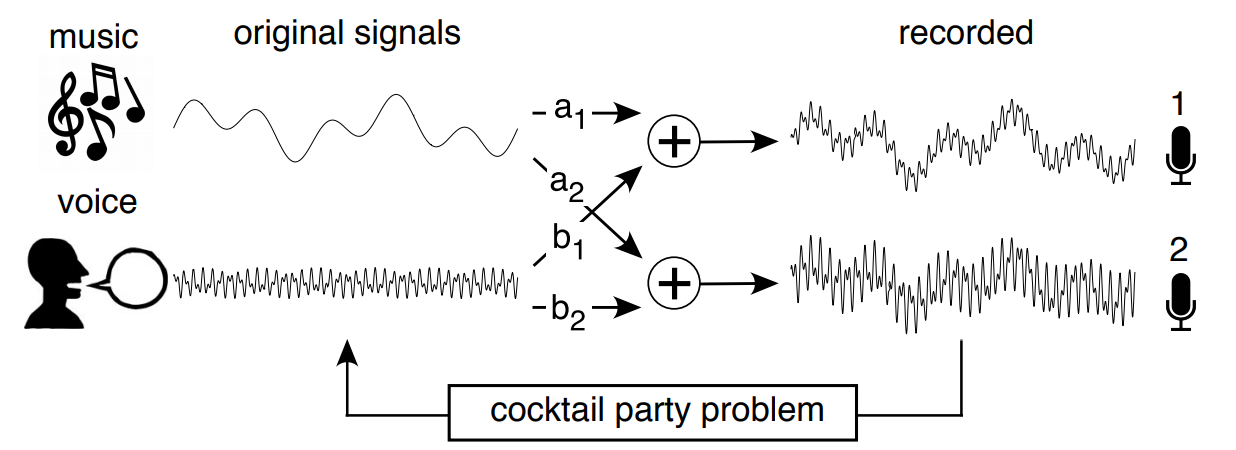
Blind source separation problem
ICA vs PCA
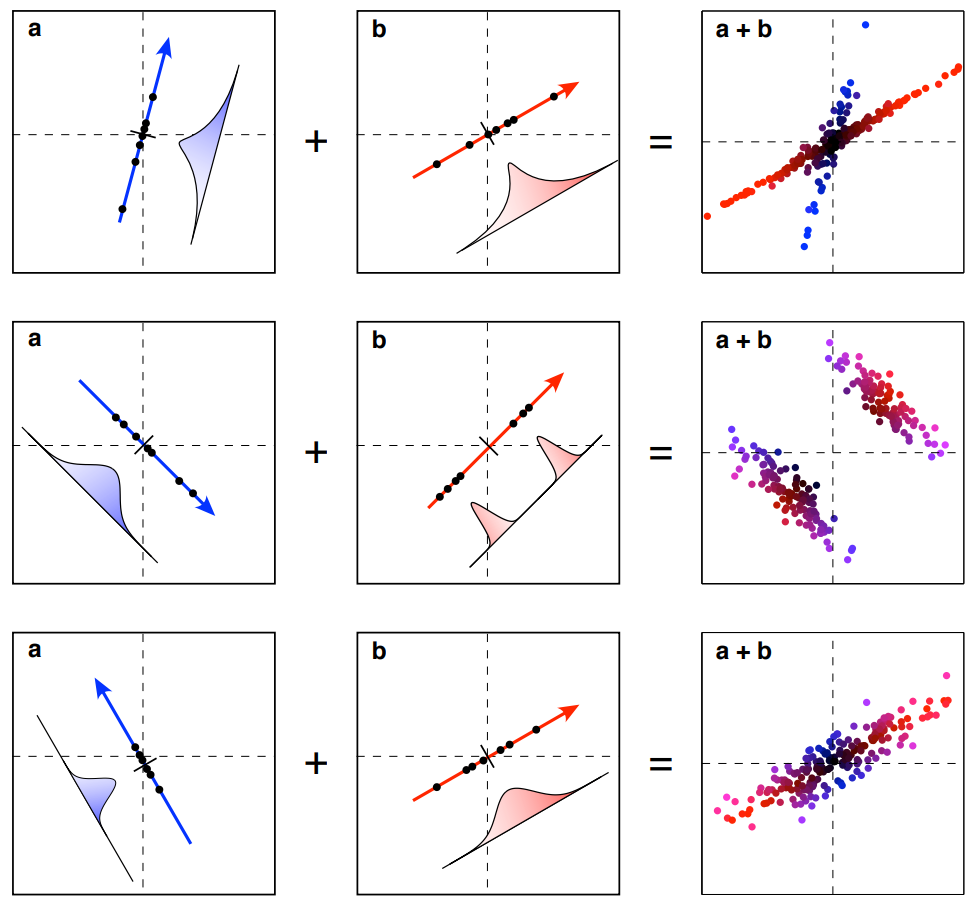
Hypothetical Simulation Data
ICA vs PCA
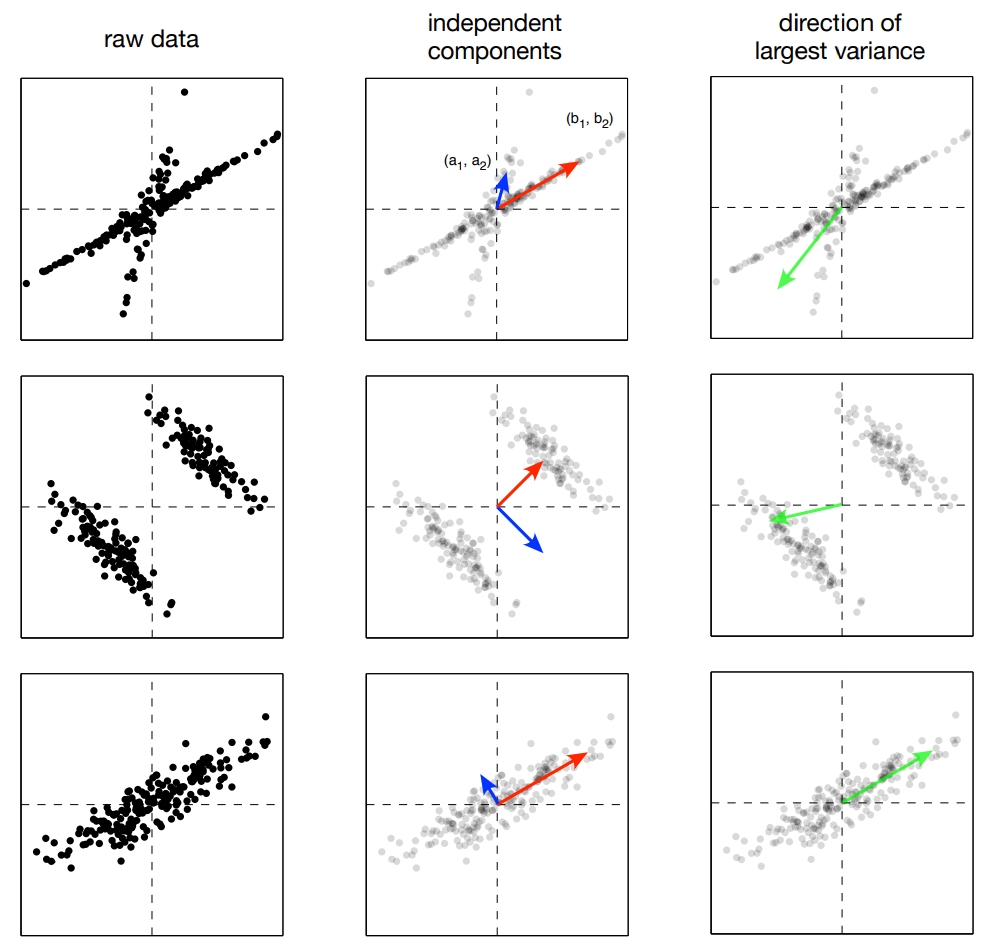
Partial ICA and PCA Results
ICA Identifiability
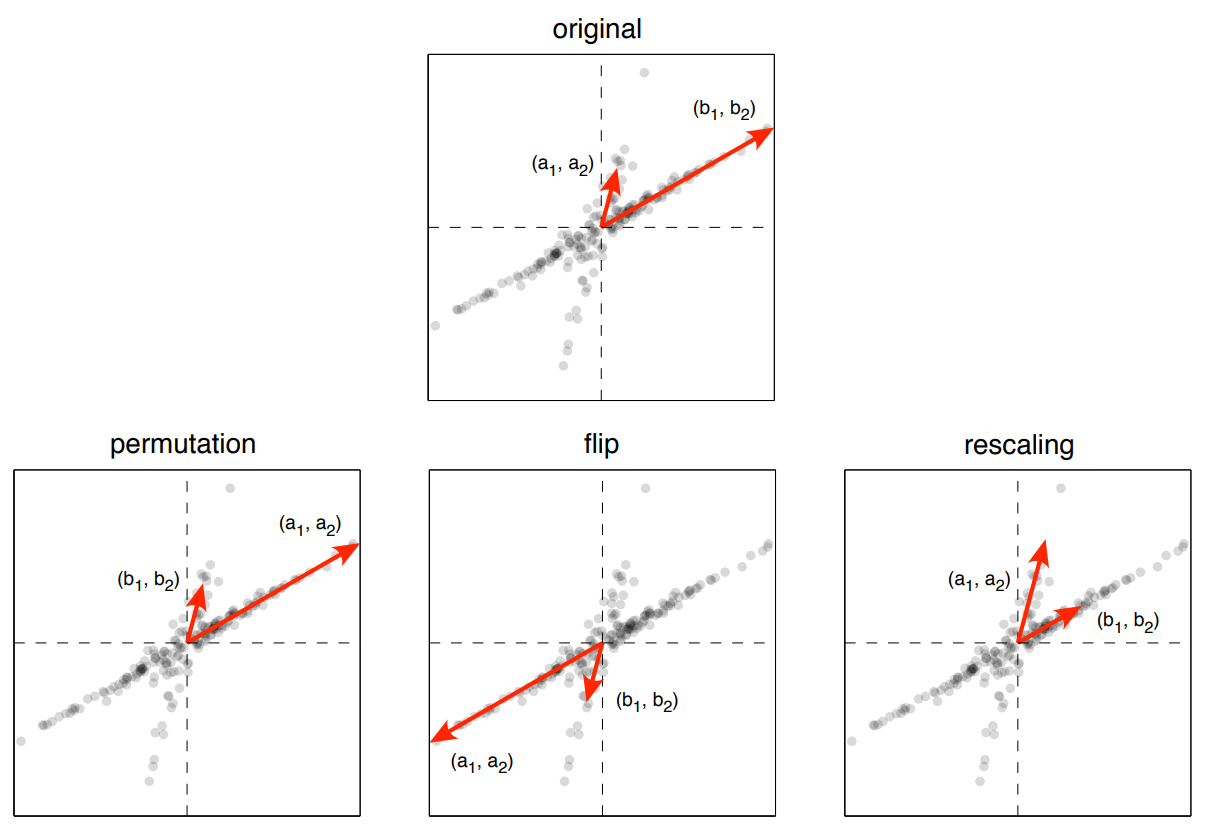
Identifiability
Eigenfaces: Data
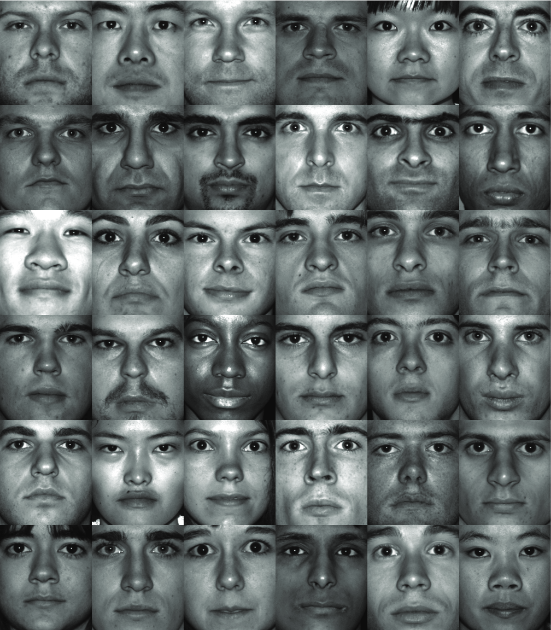
Eigenfaces example data (Brunton and Kutz 2019)
Various SVD forms
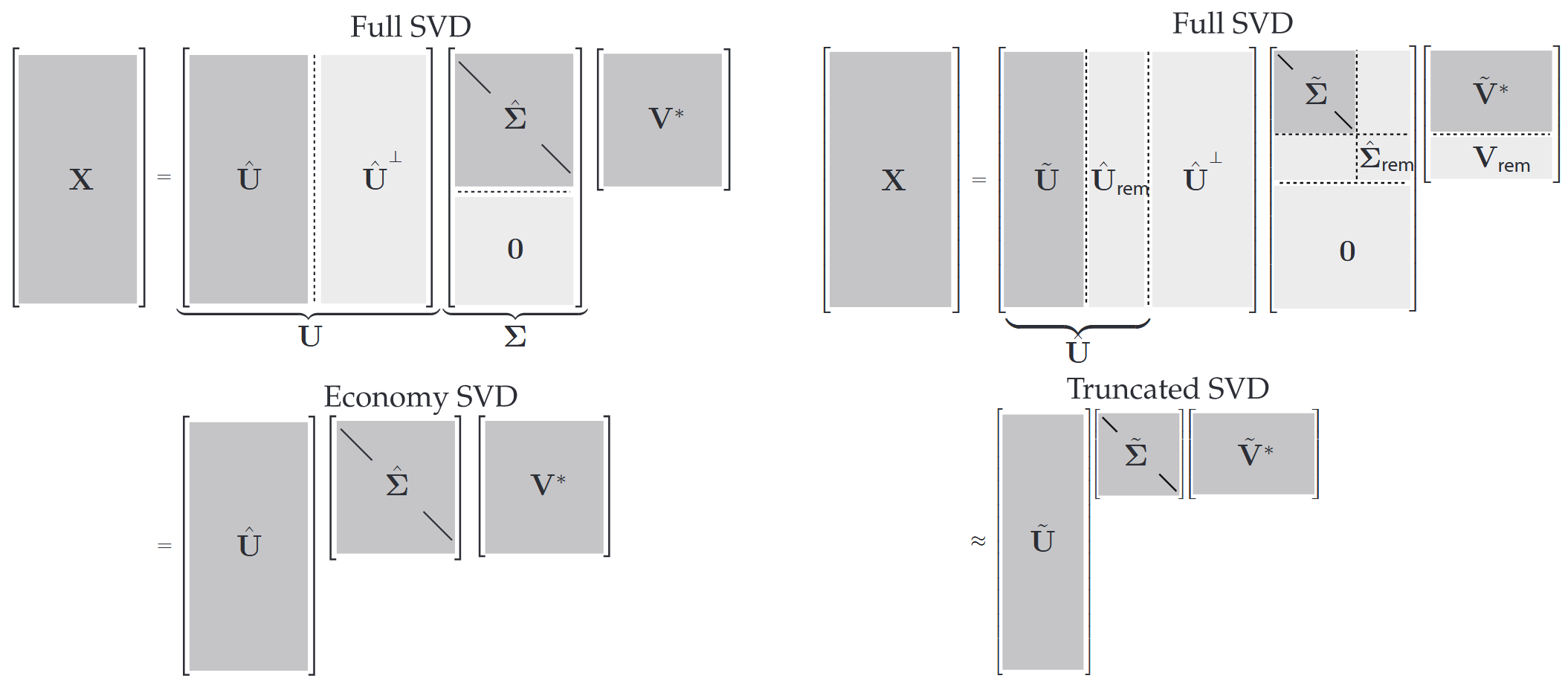
SVD forms (Brunton and Kutz 2019)
\[ \begin{aligned} X_\text{tr} \approx \hat X_\text{tr} &= U_\text{tr} \Sigma_\text{tr} V_\text{tr}^* = U_\text{tr} W_\text{tr}^* \\ X_\text{ts} \stackrel{\text{?}}{\approx} \hat X_\text{ts} &= U_\text{tr} (U_\text{tr}^* X_\text{ts}) \\ \end{aligned} \] where \(U\), \(V\), and \(\Sigma\) are from SVD (hat or tilde variations), and \(W = \Sigma V^*\).
Eigenfaces: SVD
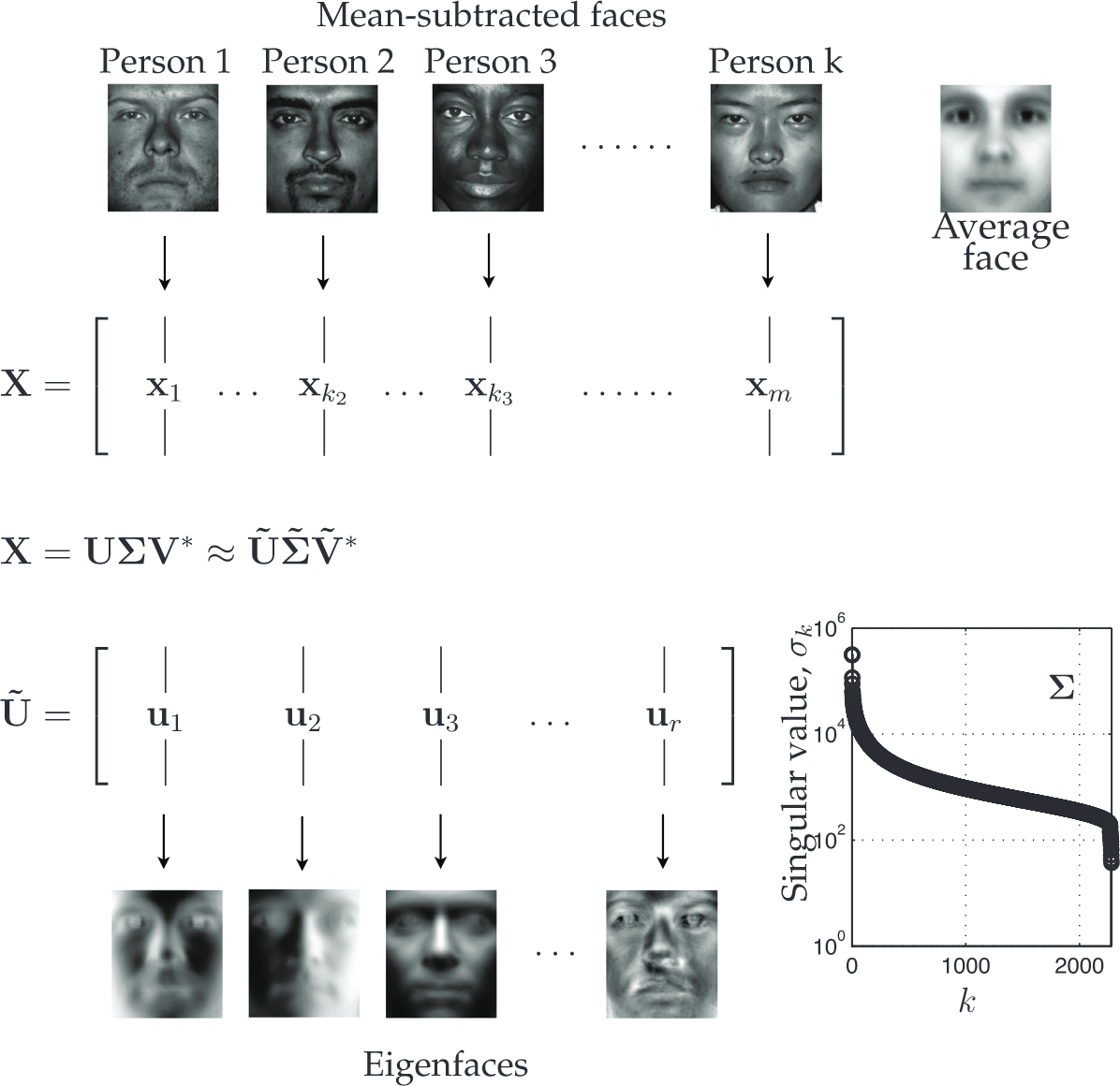
Eigenfaces and SVD (Brunton and Kutz 2019)
Eigenfaces: Reconstructing Test Image

Face test image reconstruction (Brunton and Kutz 2019)
Eigenfaces: Reconstructing Test Image

Dog test image reconstruction (Brunton and Kutz 2019)
Eigenfaces: Reconstructing Test Image
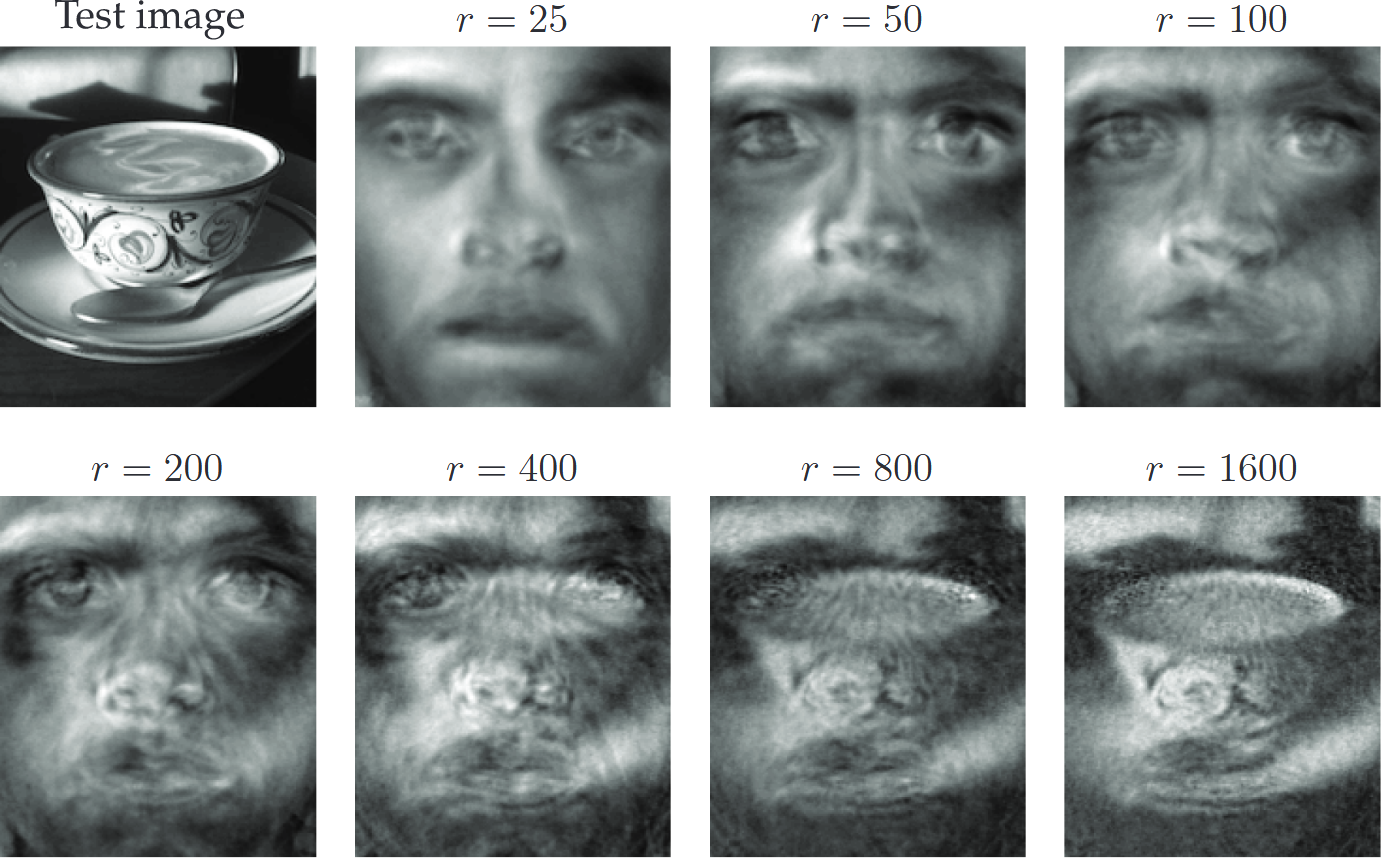
Cup test image reconstruction (Brunton and Kutz 2019)