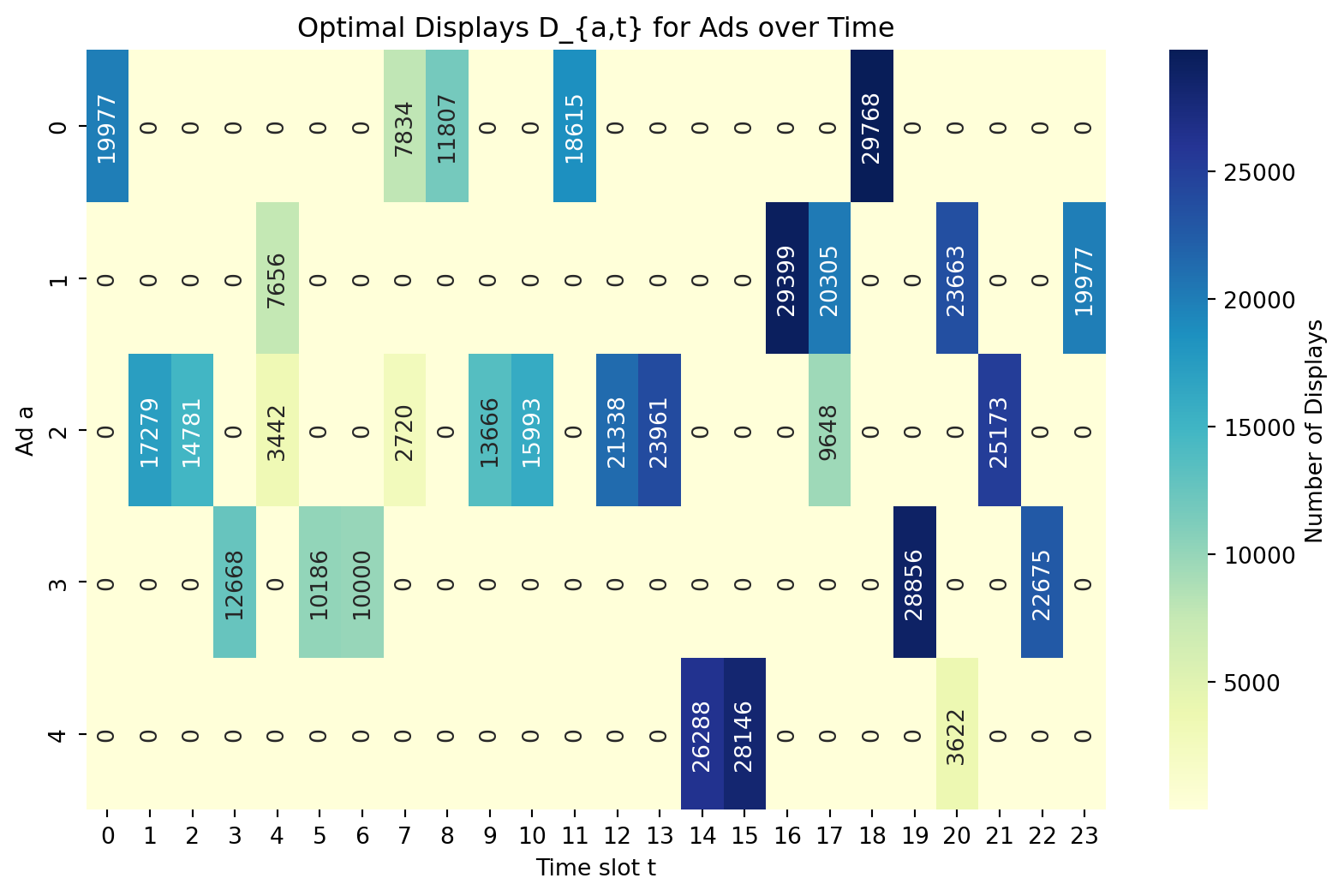
Code
import numpy as np
np.random.seed(30)
A = 5 # Number of ads
T = 24 # Number of time slots
SCALE = 10000
# Budget for ads: b_a
b = np.random.lognormal(mean=8, size=(A,)) + 10000
b = 1000 * np.round(b / 1000)
# Probability of click: p_{at} ∈ R^{AxT}
P = 0.05 * np.random.uniform(size=(A, T))
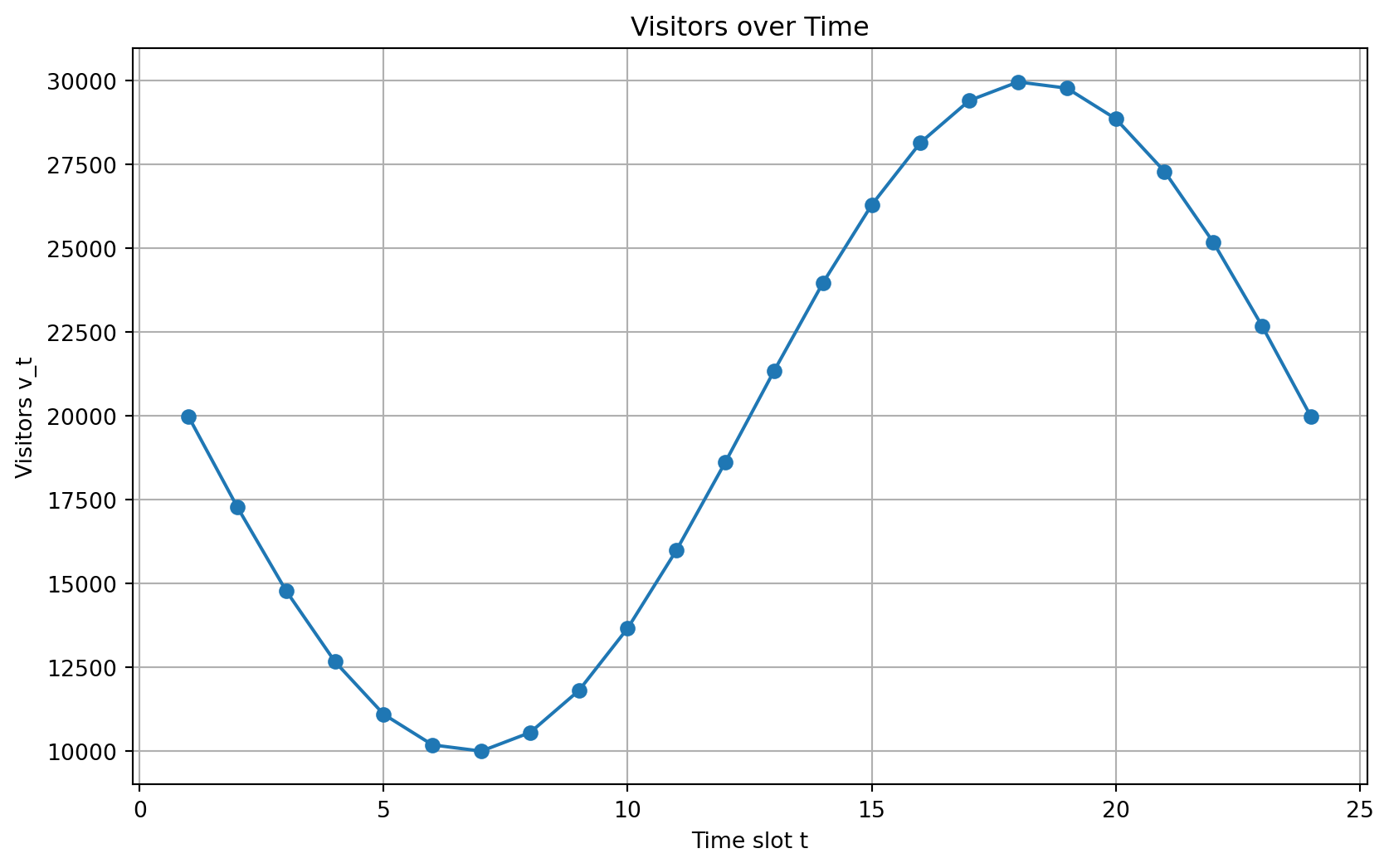
# Visitors over time: v_t ∈ R^T
v = np.sin(np.linspace(-2 * np.pi / 2, 2 * np.pi - 2 * np.pi / 2, T)) * SCALE
v += -np.min(v) + SCALE
# Contracted impressions: c_a ∈ R^A
c = np.random.uniform(size=A)
c *= 0.9 * v.sum() / c.sum()
c = 1000 * np.round(c / 1000)
# Revenue per click: r_a ∈ R^A
r = np.random.lognormal(mean=0.0, sigma=0.5, size=A)