title: "Case Study: Movie Recommender System" subtitle: PSTAT 234 (Fall 2025) format: clean-revealjs: bibliographystyle: "chicago-author-date" fig-width: 30 code-copy: hover code-line-numbers: true author:
- name: Sang-Yun Oh affiliations: "University of California, Santa Barbara" date-format: long bibliography: [../static/references.bib] execute: echo: true editor: render-on-save: true
Movie Recommender System: Latent Factor Analysis¶
Map users and movies into the same space:
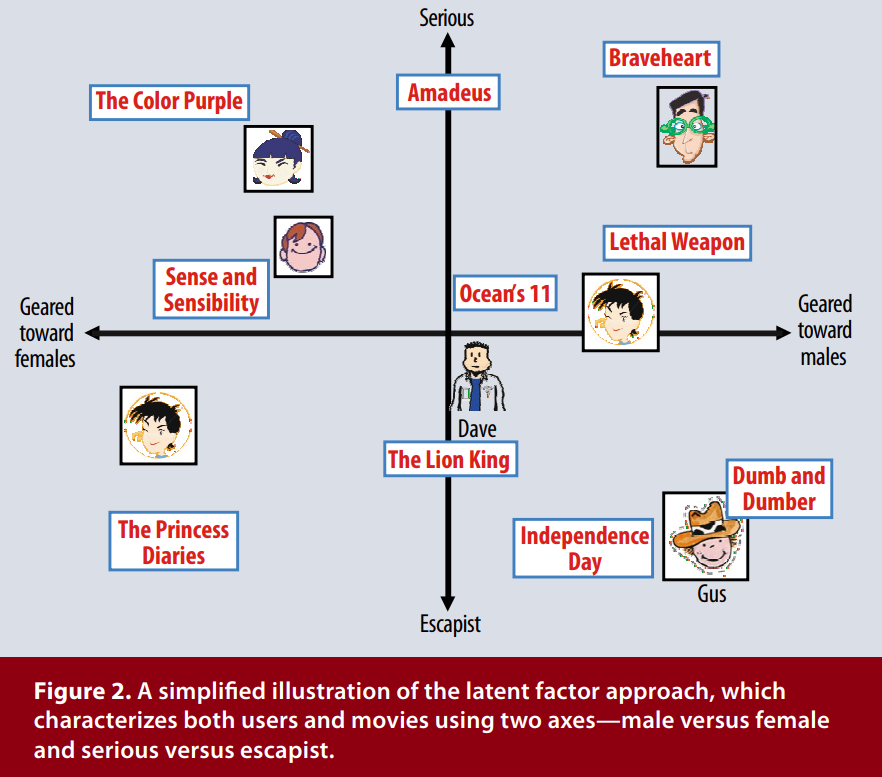
Movie Recommender System: Alternating Least Squares¶
How do we compute matrix factors $U$ and $V$?
Alternating least squares alternates between updating $U$ and $V$.
Movie Lense Data¶
Objective: build a basic recommender system using Movie Lense 100K dataset.
First, download the data:
! wget -q http://files.grouplens.org/datasets/movielens/ml-100k.zip -O movie-lense.zip\
&& unzip -o movie-lense.zip
Archive: movie-lense.zip inflating: ml-100k/allbut.pl inflating: ml-100k/mku.sh inflating: ml-100k/README inflating: ml-100k/u.data inflating: ml-100k/u.genre inflating: ml-100k/u.info inflating: ml-100k/u.item inflating: ml-100k/u.occupation inflating: ml-100k/u.user inflating: ml-100k/u1.base inflating: ml-100k/u1.test inflating: ml-100k/u2.base inflating: ml-100k/u2.test inflating: ml-100k/u3.base inflating: ml-100k/u3.test inflating: ml-100k/u4.base inflating: ml-100k/u4.test inflating: ml-100k/u5.base inflating: ml-100k/u5.test inflating: ml-100k/ua.base inflating: ml-100k/ua.test inflating: ml-100k/ub.base inflating: ml-100k/ub.test
Metadata: Rating, User, and Movie Raw Data¶
::: {.incremental}
u.data: The full u data set, 100000 ratings by 943 users on 1682 itemsu.item: Information about the items (movies).u.genre: A list of the genres.u.user: Demographic information about the usersu.occupation: A list of the occupations. :::
Raw Data: Ratings¶
File name: u.data
100000 movie ratings by 943 users on 1682 items
Columns:
user id | item id | rating | timestampData rows:
!head ml-100k/u.data
196 242 3 881250949 186 302 3 891717742 22 377 1 878887116 244 51 2 880606923 166 346 1 886397596 298 474 4 884182806 115 265 2 881171488 253 465 5 891628467 305 451 3 886324817 6 86 3 883603013
Raw Data: Movie information¶
File name: u.item
Information about the items (movies)
Columns:
movie id | movie title | release date | video release date | IMDb URL | unknown | Action | Adventure | ...Data rows:
!head -n7 ml-100k/u.item
1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0 2|GoldenEye (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?GoldenEye%20(1995)|0|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0 3|Four Rooms (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Four%20Rooms%20(1995)|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|1|0|0 4|Get Shorty (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Get%20Shorty%20(1995)|0|1|0|0|0|1|0|0|1|0|0|0|0|0|0|0|0|0|0 5|Copycat (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Copycat%20(1995)|0|0|0|0|0|0|1|0|1|0|0|0|0|0|0|0|1|0|0 6|Shanghai Triad (Yao a yao yao dao waipo qiao) (1995)|01-Jan-1995||http://us.imdb.com/Title?Yao+a+yao+yao+dao+waipo+qiao+(1995)|0|0|0|0|0|0|0|0|1|0|0|0|0|0|0|0|0|0|0 7|Twelve Monkeys (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Twelve%20Monkeys%20(1995)|0|0|0|0|0|0|0|0|1|0|0|0|0|0|0|1|0|0|0
Raw Data: User information¶
File name: u.user
Demographic information about the users
Columns:
user id | age | gender | occupation | zip codeData rows:
!head ml-100k/u.user
1|24|M|technician|85711 2|53|F|other|94043 3|23|M|writer|32067 4|24|M|technician|43537 5|33|F|other|15213 6|42|M|executive|98101 7|57|M|administrator|91344 8|36|M|administrator|05201 9|29|M|student|01002 10|53|M|lawyer|90703
#| echo: false
! python -m site
sys.path = [
'/home/jovyan/work/lecture-slides',
'/opt/conda/lib/python311.zip',
'/opt/conda/lib/python3.11',
'/opt/conda/lib/python3.11/lib-dynload',
'/opt/conda/lib/python3.11/site-packages',
]
USER_BASE: '/home/jovyan/.local' (exists)
USER_SITE: '/home/jovyan/.local/lib/python3.11/site-packages' (doesn't exist)
ENABLE_USER_SITE: True
#| code-fold: true
#| code-summary: "Reloading if module movielense.py changes"
%load_ext autoreload
%autoreload 2
Create a file with contents below:
%%writefile movielense.py
import numpy as np
import pandas as pd
from pathlib import Path
Overwriting movielense.py
Import Users¶
%%writefile -a movielense.py
def import_users(user_filename):
"""
Imports Movie Lense user data into Pandas DataFrame
user_filename: e.g. location of file `ml-100k/u.data` from
http://files.grouplens.org/datasets/movielens/ml-100k.zip
"""
users_list = [l.split('|') for l in Path(user_filename).read_text().split('\n')]
return pd.DataFrame(
users_list,
columns='user id | age | gender | occupation | zip code'.split(' | '),
).dropna().astype(
{'user id':'int', 'age':'int', 'gender':'str', 'occupation':'str', 'zip code':'str'}
).set_index('user id')
Appending to movielense.py
Import Movies¶
%%writefile -a movielense.py
def import_movies(movies_filename):
"""
Imports Movie Lense movies data into Pandas DataFrame
movies_filename: e.g. location of file `ml-100k/u.item` from
http://files.grouplens.org/datasets/movielens/ml-100k.zip
"""
movies_list = [l.split('|') for l in Path(movies_filename).read_text(encoding = "ISO-8859-1").split('\n')]
movies = pd.DataFrame(
movies_list,
columns='movie id | movie title | release date | video release date | '\
'IMDb URL | unknown | Action | Adventure | Animation | '\
'Children\'s | Comedy | Crime | Documentary | Drama | Fantasy | '\
'Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi | '\
'Thriller | War | Western'.split(' | '),
).dropna()
d = {'movie id':'int', 'movie title':'str', 'release date':'datetime64[ns]', 'video release date':'datetime64[ns]', 'IMDb URL':'str', 'Action':'int'}
genre_columns = movies.columns[-19:]
return movies.astype(d).astype(dict(zip(genre_columns, [int]*19))).astype(dict(zip(genre_columns, [bool]*19))).set_index('movie id')
Appending to movielense.py
Import Ratings¶
%%writefile -a movielense.py
def import_ratings(data_filename, movies=None):
"""
Imports Movie Lense ratings data into Pandas DataFrame
data_filename: e.g. location of file `ml-100k/u.data` from
http://files.grouplens.org/datasets/movielens/ml-100k.zip
movies: DataFrame resulting from `import_users`
"""
ratings_list = [l.split('\t') for l in Path(data_filename).read_text().split('\n')]
ratings = pd.DataFrame(
ratings_list,
columns='user id | item id | rating | timestamp'.split(' | ')
).dropna().astype({'timestamp':'int'}).astype(
{'user id':'int', 'item id':'int', 'rating':'int', 'timestamp':'datetime64[s]'}
).rename(columns={'item id':'movie id'}).set_index(['user id','movie id']).drop(columns=['timestamp'])
if (movies is not None):
ratings = ratings.join(movies['movie title'], on='movie id').set_index('movie title', append=True)
return ratings
Appending to movielense.py
:::
import pandas as pd
import altair as alt
import numpy as np
import movielense as ml
users = ml.import_users('ml-100k/u.user')
movies = ml.import_movies('ml-100k/u.item')
ratings = ml.import_ratings('ml-100k/u.data', movies)
users.head()
| age | gender | occupation | zip code | |
|---|---|---|---|---|
| user id | ||||
| 1 | 24 | M | technician | 85711 |
| 2 | 53 | F | other | 94043 |
| 3 | 23 | M | writer | 32067 |
| 4 | 24 | M | technician | 43537 |
| 5 | 33 | F | other | 15213 |
movies.head(3)
| movie title | release date | video release date | IMDb URL | unknown | Action | Adventure | Animation | Children's | Comedy | ... | Fantasy | Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi | Thriller | War | Western | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| movie id | |||||||||||||||||||||
| 1 | Toy Story (1995) | 1995-01-01 | NaT | http://us.imdb.com/M/title-exact?Toy%20Story%2... | False | False | False | True | True | True | ... | False | False | False | False | False | False | False | False | False | False |
| 2 | GoldenEye (1995) | 1995-01-01 | NaT | http://us.imdb.com/M/title-exact?GoldenEye%20(... | False | True | True | False | False | False | ... | False | False | False | False | False | False | False | True | False | False |
| 3 | Four Rooms (1995) | 1995-01-01 | NaT | http://us.imdb.com/M/title-exact?Four%20Rooms%... | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | True | False | False |
3 rows × 23 columns
ratings.head()
| rating | |||
|---|---|---|---|
| user id | movie id | movie title | |
| 196 | 242 | Kolya (1996) | 3 |
| 186 | 302 | L.A. Confidential (1997) | 3 |
| 22 | 377 | Heavyweights (1994) | 1 |
| 244 | 51 | Legends of the Fall (1994) | 2 |
| 166 | 346 | Jackie Brown (1997) | 1 |
R_all = ratings.unstack(['user id'])
R_all
| rating | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... | 934 | 935 | 936 | 937 | 938 | 939 | 940 | 941 | 942 | 943 | |
| movie id | movie title | |||||||||||||||||||||
| 1 | Toy Story (1995) | 5.0 | 4.0 | NaN | NaN | 4.0 | 4.0 | NaN | NaN | NaN | 4.0 | ... | 2.0 | 3.0 | 4.0 | NaN | 4.0 | NaN | NaN | 5.0 | NaN | NaN |
| 2 | GoldenEye (1995) | 3.0 | NaN | NaN | NaN | 3.0 | NaN | NaN | NaN | NaN | NaN | ... | 4.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 5.0 |
| 3 | Four Rooms (1995) | 4.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | 4.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | Get Shorty (1995) | 3.0 | NaN | NaN | NaN | NaN | NaN | 5.0 | NaN | NaN | 4.0 | ... | 5.0 | NaN | NaN | NaN | NaN | NaN | 2.0 | NaN | NaN | NaN |
| 5 | Copycat (1995) | 3.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1678 | Mat' i syn (1997) | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1679 | B. Monkey (1998) | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1680 | Sliding Doors (1998) | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1681 | You So Crazy (1994) | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1682 | Scream of Stone (Schrei aus Stein) (1991) | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
1682 rows × 943 columns
Create Small Subset of Data¶
Most ratings are missing: {python} np.round(np.isnan(R_all).mean().mean()*100, 2)% of ratings are missing
#| code-fold: true
#| code-summary: "Create a small subset of data"
I = 16
M = 15
# retrieve movies/users combination that is not *too* sparse
top_users = R_all.agg('sum', axis=0).nlargest(70).tail(I).index
top_movies = R_all.agg('sum', axis=1).nlargest(70).tail(M).index
R = R_all.loc[top_movies, top_users]
R
| rating | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user id | 883 | 716 | 387 | 85 | 339 | 178 | 389 | 271 | 1 | 650 | 727 | 312 | 269 | 328 | 299 | 301 | |
| movie id | movie title | ||||||||||||||||
| 132 | Wizard of Oz, The (1939) | NaN | 5.0 | NaN | 5.0 | 5.0 | NaN | 5.0 | 5.0 | 4.0 | 4.0 | 2.0 | 5.0 | 5.0 | 5.0 | NaN | 4.0 |
| 238 | Raising Arizona (1987) | 4.0 | 4.0 | 5.0 | 2.0 | 5.0 | 4.0 | 5.0 | 4.0 | 4.0 | 4.0 | 2.0 | 3.0 | 5.0 | NaN | 4.0 | NaN |
| 748 | Saint, The (1997) | 5.0 | NaN | NaN | NaN | NaN | 4.0 | NaN | NaN | NaN | NaN | 4.0 | NaN | NaN | 3.0 | NaN | NaN |
| 196 | Dead Poets Society (1989) | NaN | 5.0 | 2.0 | 4.0 | 4.0 | 4.0 | 3.0 | 4.0 | 5.0 | 4.0 | 4.0 | NaN | 1.0 | NaN | NaN | 4.0 |
| 197 | Graduate, The (1967) | 4.0 | 5.0 | 2.0 | 5.0 | 5.0 | 2.0 | 5.0 | 4.0 | 5.0 | 4.0 | 3.0 | 4.0 | 5.0 | NaN | 3.0 | 5.0 |
| 185 | Psycho (1960) | 5.0 | 5.0 | NaN | NaN | 4.0 | NaN | 5.0 | 3.0 | 4.0 | 3.0 | NaN | 5.0 | 5.0 | 4.0 | 3.0 | NaN |
| 194 | Sting, The (1973) | 3.0 | 5.0 | 3.0 | 4.0 | 4.0 | 4.0 | 4.0 | 5.0 | 4.0 | 4.0 | NaN | 4.0 | 5.0 | 3.0 | 3.0 | 4.0 |
| 742 | Ransom (1996) | NaN | NaN | 2.0 | NaN | NaN | 3.0 | NaN | 3.0 | NaN | 3.0 | NaN | NaN | NaN | 4.0 | 4.0 | 4.0 |
| 82 | Jurassic Park (1993) | 3.0 | 5.0 | 4.0 | 3.0 | 4.0 | 5.0 | 4.0 | NaN | 5.0 | 3.0 | 3.0 | NaN | 2.0 | 4.0 | NaN | 5.0 |
| 97 | Dances with Wolves (1990) | NaN | 4.0 | 2.0 | 2.0 | 4.0 | 5.0 | NaN | 5.0 | 3.0 | 3.0 | NaN | 5.0 | NaN | 3.0 | 4.0 | 4.0 |
| 475 | Trainspotting (1996) | NaN | NaN | 3.0 | NaN | 5.0 | NaN | 5.0 | NaN | NaN | NaN | NaN | NaN | 5.0 | NaN | 4.0 | NaN |
| 268 | Chasing Amy (1997) | NaN | NaN | 3.0 | 4.0 | NaN | 4.0 | NaN | NaN | 5.0 | NaN | 4.0 | NaN | 5.0 | NaN | NaN | NaN |
| 186 | Blues Brothers, The (1980) | NaN | 3.0 | 2.0 | 3.0 | 4.0 | NaN | 2.0 | 4.0 | 4.0 | 4.0 | 5.0 | 3.0 | 2.0 | 4.0 | 3.0 | 4.0 |
| 496 | It's a Wonderful Life (1946) | 2.0 | 5.0 | 3.0 | 4.0 | 5.0 | NaN | 4.0 | 5.0 | NaN | 4.0 | NaN | 5.0 | 5.0 | NaN | 3.0 | 5.0 |
| 111 | Truth About Cats & Dogs, The (1996) | NaN | 4.0 | NaN | NaN | NaN | 4.0 | 3.0 | 4.0 | 5.0 | NaN | 3.0 | NaN | 1.0 | NaN | 3.0 | 1.0 |
Visualizing Missing Values¶
Zeros indicate missing ratings. To visualize the missing values, plot the following heatmap
#| code-fold: true
#| code-summary: "Visualize missing rating values"
long = lambda x: x.stack().reset_index()
# https://altair-viz.github.io/user_guide/encoding.html#encoding-data-types
alt.Chart(long(R)).mark_rect().encode(
x='user id:O',
y='movie title:O',
color=alt.Color('rating:O', scale=alt.Scale(scheme='yellowgreenblue'))
)
/tmp/ipykernel_2933879/2524743408.py:4: FutureWarning: The previous implementation of stack is deprecated and will be removed in a future version of pandas. See the What's New notes for pandas 2.1.0 for details. Specify future_stack=True to adopt the new implementation and silence this warning. long = lambda x: x.stack().reset_index()
Scalar Ratings: Users and Movies¶
Model rating $r_{mi}$ of movie $m$ by user $i$: $$ \hat r_{mi} = \sum_{k=1}^K v_{mk} u_{ik} = v_{m} u_{i}^T $$
- $K$ unobserved characteristics (latent factors)
- Characteristic index: $k=1,\dots,K$
- $v_m=(v_{m1},\dots,v_{mK})$: $K$-vector for movie $m$
- $u_i=(u_{i1},\dots,u_{iK})$: $K$-vector for user $i$
- Rating $r_{mi}$ is high if $v_m$ and $u_i$ are well-aligned
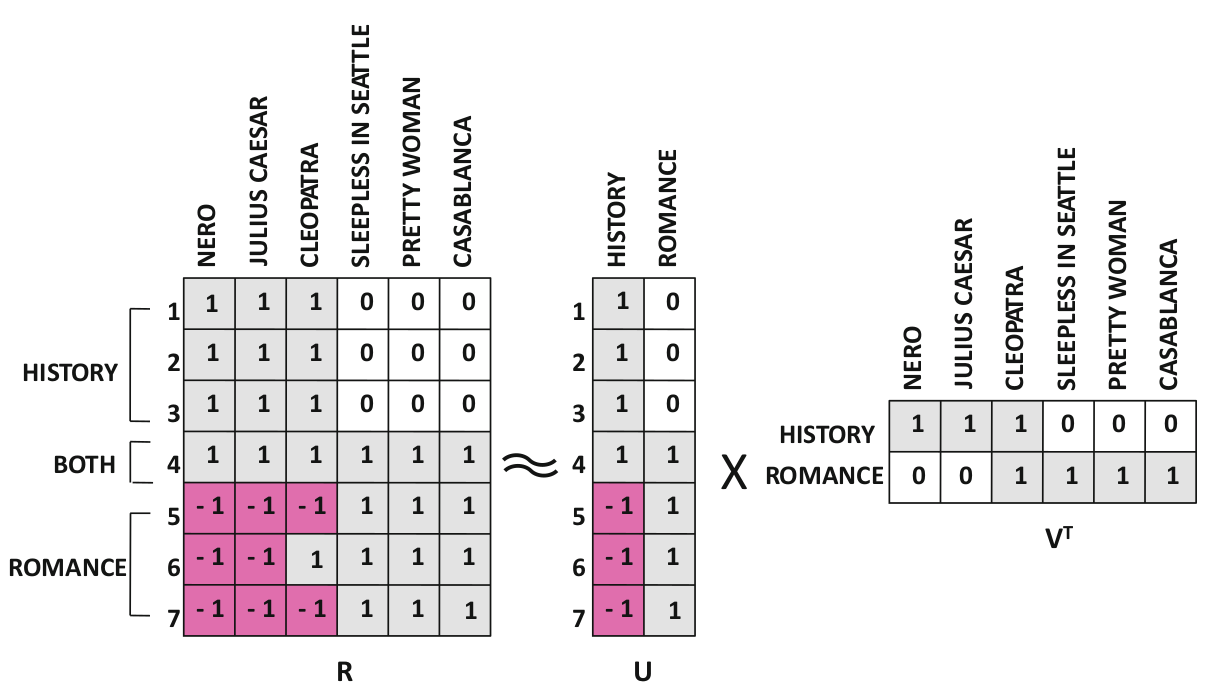
Ratings Matrix: Users and Movies Matrices¶
$U$ and $V$ as matrix factors
$$ \begin{aligned} &\min_{U,V} \|R - V U^T\|_F^2 \end{aligned} $$
- Ratings matrix $R$: size $M\times I$
- Movies matrix $V$: size $M\times K$
- Users matrix $U$: size $I\times K$
Ratings Matrix: Users and Movies Matrices¶
Evaluate objective function for observed $r_{mi}$ only: $$ \begin{aligned} \min_{U,V} \|R - V U^T\|_F^2 =\min_{U,V} \left\{ \sum_{m=1}^M \sum_{i=1}^I I_{mi}(r_{mi} - v_m u_i^T)^2 \right\}, \end{aligned} $$ where $$ \begin{aligned} I_{mi} = \begin{cases} 1 \text{, if $r_{mi}$ is observed}\\ 0 \text{, otherwise}\\ \end{cases} \end{aligned} $$
Now, iteratively compute optimal solutions $U$ and $V$
Optimize to find best $U$ and $V$¶
- $f(U,V)$ is sum of convex functions $\Rightarrow$ update each $f_{ij}(u_i,v_m)$
- Compute the gradients:
$$ \begin{aligned} \frac{\partial}{\partial u_i} f_{mi}(v_m,u_i) &= -2(r_{mi} - v_mu_i^T)\cdot v_m\\ \frac{\partial}{\partial v_m} f_{mi}(v_m,u_i) &= -2(r_{mi} - v_mu_i^T)\cdot u_i. \end{aligned} $$ - Gradient descent updates are, $$ \begin{aligned} u_i^{\text{new}} &= u_i + 2\alpha(r_{mi} - v_m u_i^T)\cdot v_m\\ v_m^{\text{new}} &= v_m + 2\alpha(r_{mi} - v_m u_i^T)\cdot u_i, \end{aligned} $$ where $\alpha$ is the step-size
Preparing to Optimize: Part 1¶
- Decide number of latent factors $k$
- Initialize matrices $U$ and $V$ with random values
#| code-fold: show
# number of latent factors
K = 3
# initialize U and V with random values
np.random.seed(42)
U = np.random.uniform(0, 1, size=K*I).reshape((I, K))
V = np.random.uniform(0, 1, size=K*M).reshape((M, K))
Uold = np.zeros_like(U)
Vold = np.zeros_like(V)
U.shape
(16, 3)
Preparing to Optimize: Part 2¶
- Decide metric for improvement (root mean square error): $$ \text{RMSE}(x, y) = \left[\frac{1}{n}\sum_{i=1}^{n} \|x_i - y_i\|_2^2 \right]^{1/2},$$ where matrices $x$ and $y$ are first vectorized
#| code-fold: show
# calculate RMSE
def rmse(X, Y):
from numpy import sqrt, nanmean
return sqrt(nanmean((X - Y)**2))
error = [(0, rmse(R, np.inner(V,U)))]
Preparing to Optimize: Part 3¶
- Keep track of updates to $U$ and $V$: $$ \text{MaxUpdate}(U^{\text{(old)}}, U^{\text{(new)}}) = \left\|\frac{U^{\text{(old)}}-U^{\text{(new)}}}{U^{\text{(new)}}}\right\|_\infty,$$ where difference, ratio, and matrix norm is computed element-wise.
#| code-fold: show
# calculate maximum magnitude of relative updates
def max_update(X, Y):
from numpy import inf
from numpy.linalg import norm
return norm(((X - Y)/Y).ravel(), inf)
update = [(0, max(max_update(Uold, U), max_update(Vold, V)))]
Compute Solutions: $U$ and $V$¶
#| code-fold: show
rate = 0.1 # learning rate (step size)
max_iterations = 300 # maximum number of iterations
threshold = 0.001 # max_update threshold for termination
for t in range(1, max_iterations):
for m, i in zip(*np.where(~np.isnan(R))):
U[i] = U[i] + rate*V[m]*(R.iloc[m,i] - np.inner(V[m], U[i]))
V[m] = V[m] + rate*U[i]*(R.iloc[m,i] - np.inner(V[m], U[i]))
# compute error after one sweep of updates
error += [(t, rmse(R, np.inner(V,U)))]
# keep track of how much U and V changes
update += [(t, max(max_update(Uold, U), max_update(Vold, V)))]
Uold = U.copy()
Vold = V.copy()
error = pd.DataFrame(error, columns=['iteration', 'rmse'])
update = pd.DataFrame(update , columns=['iteration', 'maximum update'])
Monitoring Optimization Progress¶
As gradient descent progresses,
- $U$ and $V$ are updated. How large are the updates?
- Are the updates getting better? Does RMSE decrease?
f_rmse = alt.Chart(error).encode(x='iteration:Q', y=alt.Y('rmse:Q', scale=alt.Scale(type='log', base=10, domain=[0.1, 3])))
# f_update = alt.Chart(update).encode(x='iteration:Q', y='maximum update:Q')
f_update = alt.Chart(update).encode(x='iteration:Q', y=alt.Y('maximum update:Q', scale=alt.Scale(type='log', base=10)))
alt.hconcat(
alt.layer(f_rmse.mark_line(), f_rmse.mark_point(filled=True), title='Root Mean Square Error'),
alt.layer(f_update.mark_line(), f_update.mark_point(filled=True), title='Maximum Relative Update')
)
Visualize Results¶
Comparison Data Frame:
observed: observed ratings , $R$fit: calculated ratings $\hat r_{mi}$ if $r_{mi}$ is observedfit/prediction: $\hat R = VU^T$deviation: $(\hat r_{mi} - r_{mi})\cdot I_{mi}$, where $I_{mi}$ indicates if user $i$ rated movie $m$
#| echo: false
# Rone is DataFrame of all ones with R's structure
Rone = pd.DataFrame().reindex_like(R).replace(np.nan, 1)
# multiplying by Rone copies DataFrame structure
Rhat = np.inner(V, U) * Rone
Rhat_if_obs = Rhat.where(~np.isnan(R), np.nan)
R_compare = \
R.rename(columns={'rating':'observed'})\
.join(Rhat_if_obs.rename(columns={'rating':'fit'}))\
.join(Rhat.rename(columns={'rating':'fit/prediction'}))\
.join((Rhat_if_obs-R).rename(columns={'rating':'deviation'}))
long(R_compare).head(3)
/tmp/ipykernel_2933879/2524743408.py:4: FutureWarning: The previous implementation of stack is deprecated and will be removed in a future version of pandas. See the What's New notes for pandas 2.1.0 for details. Specify future_stack=True to adopt the new implementation and silence this warning. long = lambda x: x.stack().reset_index()
| movie id | movie title | user id | observed | fit | fit/prediction | deviation | |
|---|---|---|---|---|---|---|---|
| 0 | 132 | Wizard of Oz, The (1939) | 1 | 4.0 | 4.435839 | 4.435839 | 0.435839 |
| 1 | 132 | Wizard of Oz, The (1939) | 85 | 5.0 | 4.677426 | 4.677426 | -0.322574 |
| 2 | 132 | Wizard of Oz, The (1939) | 178 | NaN | NaN | 3.566235 | NaN |
Recommending Movies¶
Recommendation: unwatched movie $m$ with highest $\hat r_{mi}$
#| echo: false
# create new base plot
base = alt.Chart(long(R_compare)).mark_rect().encode(
x='user id:O',
y='movie title:O',
tooltip=['user id', 'movie title', 'fit/prediction', 'observed', 'deviation']
)
# raw ratings data
f_raw = base\
.properties(title='Ratings Data')\
.encode(color=alt.Color('observed:O', scale=alt.Scale(scheme='yellowgreenblue', domain=[1,2,3,4,5])))
# fit and predicted ratings
f_all = base\
.properties(title='Ratings Fit and Predictions')\
.encode(color=alt.Color('fit/prediction:Q', scale=alt.Scale(scheme='yellowgreenblue', domain=[1, 5])))
# deviation between ratings data and fit
f_err = base\
.properties(title='Deviation: Data - Fit')\
.encode(color=alt.Color('deviation:Q', scale=alt.Scale(scheme='redblue', domain=[-2, 2])))
nearest = alt.selection_point(nearest=True, on='mouseover', empty=False)
selectors = base.mark_square(filled=False, size=350).encode(
x='user id:N',
y='movie title:N',
color=alt.value('black'),
opacity=alt.condition(nearest, alt.value(1), alt.value(0))
).add_params(
nearest
)
alt.hconcat(
alt.layer(f_all.encode(color=alt.Color('fit/prediction:Q', legend=None, scale=alt.Scale(scheme='yellowgreenblue', domain=[1, 5]))),
selectors),
alt.layer(f_raw.encode(y=alt.Y('movie title:O', axis=alt.Axis(labels=False))),
selectors),
).resolve_scale(color='independent')
/tmp/ipykernel_2933879/2524743408.py:4: FutureWarning: The previous implementation of stack is deprecated and will be removed in a future version of pandas. See the What's New notes for pandas 2.1.0 for details. Specify future_stack=True to adopt the new implementation and silence this warning. long = lambda x: x.stack().reset_index()
Recommendation: User id 85¶
| Watched | Recommend | Recommend |
|---|---|---|
| 5 (observed) / 5.5 (fit/prediction) | 5.8 (fit/prediction) | 4.3 (fit/prediction) |
 |
 |
 |
| The Wizard of Oz (1939) | Truth About Cats & Dogs (1996) | Trainspotting (1996)
Recommendation: User id 727¶
| Watched | Recommend | Recommend |
|---|---|---|
| 5 (observed) / 5.2 (fit/prediction) | 5.8 (fit/prediction) | 4.6 (fit/prediction) |
 |
 |
 |
| The Blues Brothers (1980) | Dances with Wolves (1990) | It's a Wonderful Life (1946) |
Visualizing Errors¶
#| echo: false
selectors = base.mark_square(filled=False, size=350).encode(
x='user id:N',
y='movie title:N',
color=alt.value('black'),
opacity=alt.condition(nearest, alt.value(1), alt.value(0))
).add_params(
nearest
)
alt.hconcat(
alt.layer(f_all.encode(color=alt.Color('fit/prediction:Q', legend=None, scale=alt.Scale(scheme='yellowgreenblue', domain=[1, 5]))),
selectors),
alt.layer(f_err.encode(y=alt.Y('movie title:N', axis=alt.Axis(labels=False))),
selectors),
).resolve_scale(color='independent')
Comparing Users or Comparing Movies¶
- $K$-latent factors or unobserved characteristics
- $v_{mk}$: movie $m$ having characteristic $k$
- $u_{ik}$: user $i$'s affinity to characteristic $k$
$$ \hat r_{mi} = \sum_{k=1}^K v_{mk} u_{ik} = v_{m} u_{i}^T $$
Matrix Factors: $V$ and $U$¶
Compare users in $U$ and movies in $V$:
- Users $i$ and $j$ pair: $\|u_i - u_j\|^2_2$
- Movies $m$ and $n$ pair: $\|v_m - v_n\|^2_2$
#| echo: false
V = pd.DataFrame(V, index=R.index,
columns=pd.MultiIndex.from_product([['affinity'], range(0, K)], names=[None, 'k']))
U = pd.DataFrame(U, index=R.columns.get_level_values(level='user id'),
columns=pd.MultiIndex.from_product([['affinity'], range(0, K)], names=[None, 'k']))
alt.hconcat(
alt.Chart(long(V)).mark_rect().encode(x='k:N', y='movie title:N', color='affinity:Q'),
alt.Chart(long(U)).mark_rect().encode(x='k:N', y='user id:N', color='affinity:Q')
)
/tmp/ipykernel_2933879/2524743408.py:4: FutureWarning: The previous implementation of stack is deprecated and will be removed in a future version of pandas. See the What's New notes for pandas 2.1.0 for details. Specify future_stack=True to adopt the new implementation and silence this warning. long = lambda x: x.stack().reset_index() /tmp/ipykernel_2933879/2524743408.py:4: FutureWarning: The previous implementation of stack is deprecated and will be removed in a future version of pandas. See the What's New notes for pandas 2.1.0 for details. Specify future_stack=True to adopt the new implementation and silence this warning. long = lambda x: x.stack().reset_index()
What can be improved?¶
- As $k$ increases, training error $\text{RMSE}\rightarrow 0$
- Elements in $\hat R$, $U$, and $V$ may get large in magnitude
- Elements of $\hat R$ can be outside allowed range: i.e., $\hat R\not\in [1, 5]$
- $\text{RMSE}$ can increase back up as $t$ increases for large $k$